

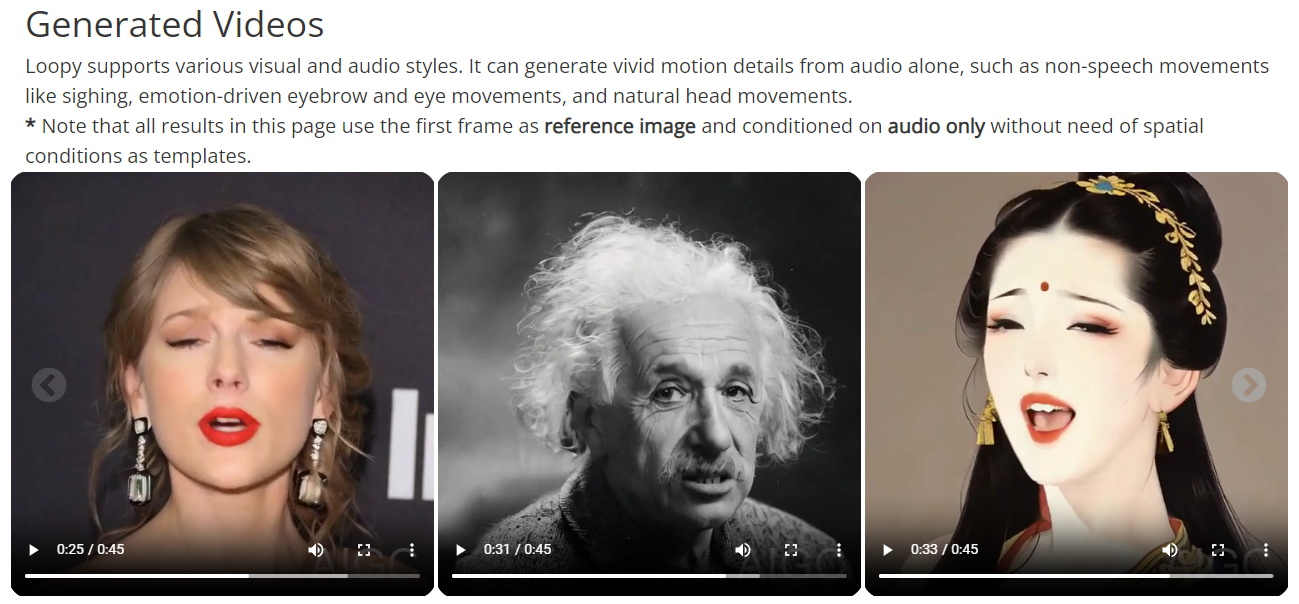
오디오 기반 얼굴, 립싱크 비디오 생성AI, Loopy 공개
틱톡을 서비스하고 있는 중국의 IT기업 바이트댄스와 절강대학이 오디오 기반의 얼굴 모션 생성AI, Loopy를 공개했습니다. 기존의 오디오 기반 비디오 생성 모델은 얼굴의 위치나 각도 같은 정보를 바탕으로 움직임을 만들어내는 방식이었습니다. 하지만 이 방식은 다양한 각도와 동작을 자연스럽게 표현하는 데 한계가 있었는데요. Loopy는 이런 공간적 정보 없이도 오디오 신호만으로 자연스럽고 현실감 있는 움직임을 만들어낼 수 있다고 합니다. 아래의 영상은 연구진이 공개한 영상입니다.
한숨을 쉰다던지, 비언어적인 움직임과 감정에 따른 표정의 변화, 자연스러운 머리의 움직임을 확인할 수 있습니다. 해당 결과물은 참조 이미지를 사용하고 오디오로 생성했다고 합니다. 이밖에도 빠르거나, 차분한 노래 등 다양한 오디오를 기반으로 동일한 이미지에 대한 움직임을 생성할 수 있습니다.
Loopy end-to-end, 작동원리
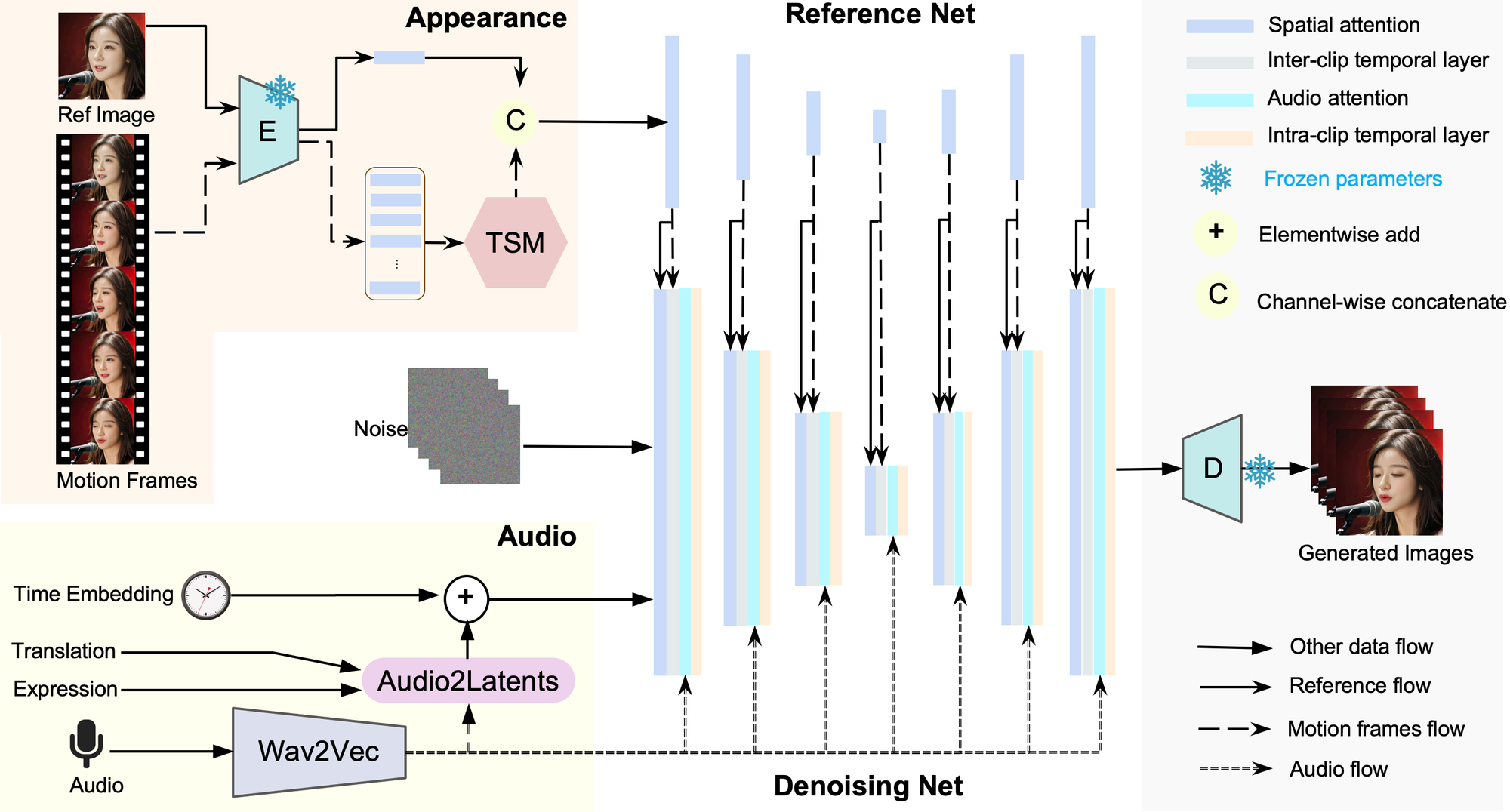
Loopy는 오디오 기반 비디오 생성 AI로 오디오 신호를 분석해 음성에 알맞는 비디오를 자동으로 생성하는 end-to-end 방식을 사용합니다. end-to-end란, 전체 프로세스를 하나의 시스템으로 연결해 동작하는 방식을 말합니다. 즉, Loopy는 오디오 입력부터 비디오 출력까지 일관된 흐름을 유지해 별도의 추가 처리 없이 자연스럽게 얼굴의 움직임과 표정을 생성합니다.
이 과정에서 Wav2Vec이 오디오를 분석하고, 분석한 것을 토대로 얼굴의 움직임을 예측하며, 오디오 - 비디오의 일관성을 높이는 과정을 거칩니다.
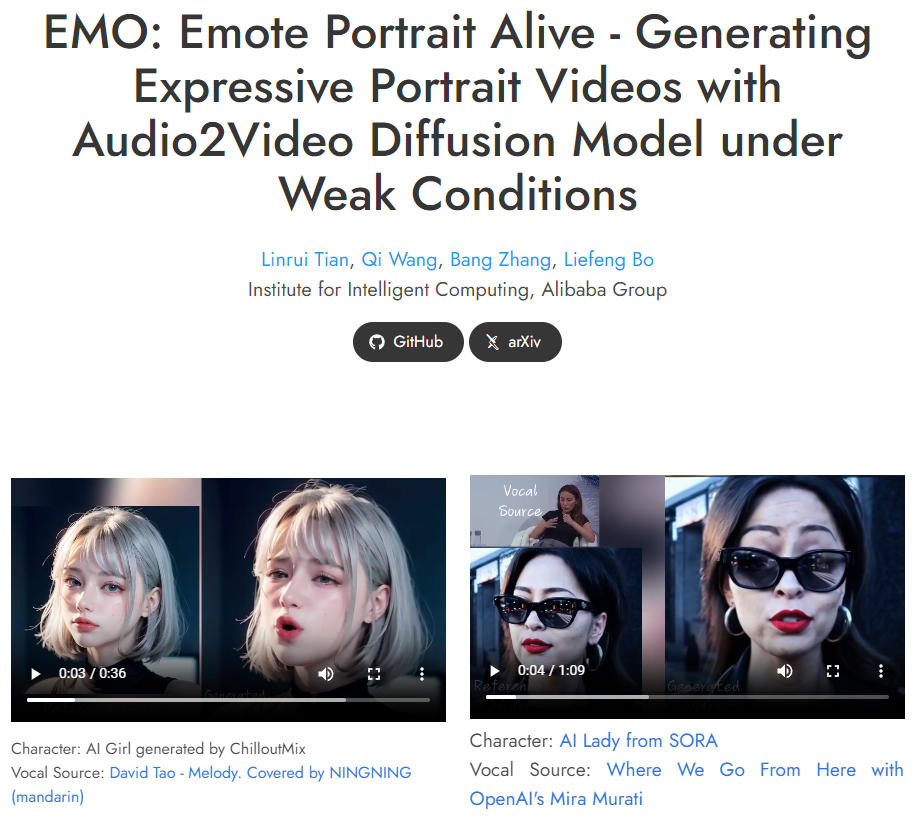
24년 2월에 공개되었던 EMO는 Audio2Video Diffusion을 활용했습니다. 음성 데이터를 통해 인물의 표정을 자연스럽게 생성하는 방식을 사용해, 안정적인 성능을 제공하는 데 중점을 둔 초기 모델입니다. 반면 Loopy는 end-to-end 방식을 활용해 더 풍부한 표현과 움직임, 일관성을 개선한 모델입니다.
다양한 모델을 비교한 영상
향후 영화 및 다양한 콘텐츠에 활용될 가능성이 높은 AI모델이라 생각됩니다. 다만 아쉽게도, 현재 Loopy의 코드와 데모 버전은 공개되지 않았습니다.
Loopy 링크: https://loopyavatar.github.io/
부루퉁의AI 네이버 블로그: https://blog.naver.com/ldlquddnr
부루퉁의 업데이트되는 챗GPT 전자책: https://vo.la/blbLY
GenAI Innovation Korea 2024 컨퍼런스!
- 일정: 10월 4일
- 장소: 서울 양재 aT 센터
- 해외 기업(프리픽, 매그니픽AI) 국내 AI 유명 연사들 강연 예정, 참가형 컨퍼런스로서 뮤직 비디오, 이미지 생성 대회
- 자세한 내용은 아래 페이지 참고하세요!
- 해외 AI 트렌드 및 앞으로의 방향 어려운 기술 컨퍼런스가 아닌 정말 대중적인 컨퍼런스로서 실질적인 정보를 원하시면 꼭 참여하세요!


뉴스레터 광고 공간 (광고주를 모집합니다)
For newsletter banner advertising inquiries, please contact: Bopyo@aikoreacommunity.com
이곳에 서비스를 소개하세요!
뉴스레터 배너 광고 문의: Bopyo@aikoreacommunity.com
뉴스레터 편집장 소개
- 보표 홈페이지
- https://amzbopyo.com/
- 보표 SNS
- 보표 레터: https://www.bopyoletters.com/
- X(트위터): https://twitter.com/AIBopyo
- 스레드: https://www.threads.net/@bopyo.amz
- 링크드인: https://www.linkedin.com/in/bopyo-park-848631231/
- 인스타그램: https://www.instagram.com/bopyo.amz/
- AI 코리아 커뮤니티 아카데미
- https://app.aikoreacommunity.com/collections/932400
{kind=link}