


오픈AI GPT-4.5 출시! 무엇이 다를까? 시스템 카드 리뷰와 커뮤니티 반응들

안녕하세요, 에코 뉴스레터 구독자 여러분.
보표입니다. 오늘 오픈AI에서 GPT-4.5를 공개했습니다. 프로 유저에게 제공이 된다고 하는데 저도 프로 유저이지만 아직 사용은 안되고 있습니다. 이번에 GPT-4.5의 시스템 카드도 함께 공개했는데요. 이번 발표를 통해 GPT-4.5가 기존 GPT-4o 대비 어떤 발전을 이뤄냈는지, 그리고 이 모델이 어떤 가능성과 한계를 지니고 있는지를 자세히 살펴보겠습니다.
*시스템 카드(System Card)는 AI 모델이나 시스템의 특성, 성능, 한계, 그리고 잠재적 위험을 투명하게 문서화한 보고서입니다. 이는 주로 다음과 같은 목적으로 사용됩니다. 시스템 카드는 OpenAI, Google, Meta 등 주요 AI 기업들이 새로운 모델을 출시할 때 함께 발표하는 일종의 표준 관행이 되었습니다. 이는 AI 기술의 책임 있는 발전과 사용을 촉진하기 위한 중요한 도구로 간주됩니다.
1. GPT-4.5란 무엇인가?
GPT-4.5는 OpenAI가 공개한 가장 크고 지식이 풍부한 대규모 언어 모델로서, 기존 GPT-4o를 기반으로 한층 더 진화한 형태입니다. 연구 미리보기(Research Preview) 형식으로 배포되어, 사용자 피드백을 모으며 더욱 정교하게 발전할 예정이라고 합니다.
- 더 자연스러운 대화: 대화에서 인간의 감정을 읽고, 그에 맞춰 답변하는 능력이 향상되었습니다.
- 감정 지능 강화: 좌절감을 완화하거나 감정적으로 힘든 질문에 대해 좀 더 인간적인 조언과 공감을 보여줍니다.
- 환각(Hallucination) 감소: 사실에 근거하지 않은 답변(환각)이 줄어들어 신뢰도가 향상되었습니다.
- 창의성 강화: 글쓰기, 디자인, 프로그래밍 등에서 좀 더 혁신적인 아이디어를 제시합니다.
솔직히 GPT-4o도 꽤나 높은 수준의 답변을 제공했지만, GPT-4.5는 그 범위를 넓히고 대화 톤이나 깊이에서 한 단계 더 발전한 모습을 보인다는 점이 큰 차별점 같습니다. 추가로 창의성 글쓰기 강화되었다고 하는데 이 부분을 기대해봅니다.
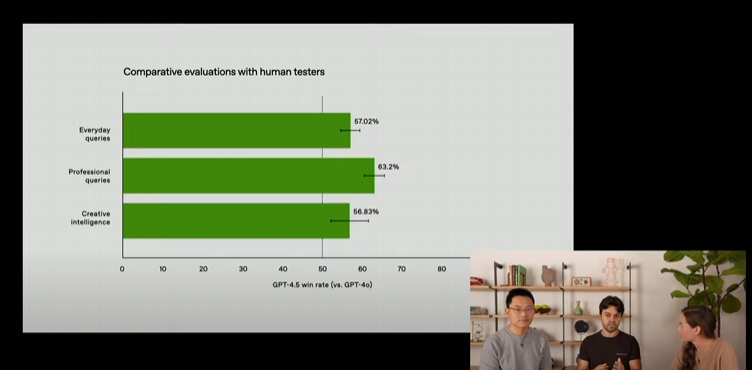
2. 개발 과정과 학습 방식
- 비지도 학습(확장)
GPT-4.5는 비지도 학습을 대규모로 확장하여, “세계 모델”의 정확도를 높였습니다. 이로써 연상 사고(Associative Thinking)가 강화되고, 환각 비율이 줄어들었다고 하네요. - 새로운 정렬(Alignment) 기법
모델이 복잡한 문제를 해결할수록 인간의 의도를 정확히 파악해야 하는데, 이번에 도입된 신규 정렬 기술로 조종 가능성(Steerability)과 뉘앙스 이해가 크게 개선되었습니다. GPT-4o에서는 “이 부분을 좀더 상세히 알려줘”라고 하면 가끔 빗나갔지만, GPT-4.5는 좀더 정밀하게 반응하는 모습을 보여줄 것 같습니다. - 데이터셋과 처리 과정
공개 데이터부터 독점 데이터, 사내 맞춤형 데이터셋까지 폭넓게 학습에 활용했습니다. 특히 개인정보 및 민감 콘텐츠 필터링을 강화하면서도 모델의 지식 폭을 극대화했다고 합니다.

3. 안전성 평가와 도전 과제
OpenAI는 GPT-4.5를 배포하기 전 상당히 광범위한 안전성 검증을 진행했습니다.
- 허용되지 않는 콘텐츠(혐오, 불법 조언 등) 생성 여부: GPT-4o 대비 크게 나쁘지 않으며, 비슷한 수준의 안전성을 유지한다고 밝혔습니다.
- 탈옥(Jailbreak) 강건성: 적대적 프롬프트(유해한 요청)를 통한 우회 공격에 대해서도 GPT-4o와 유사한 수준의 방어력을 갖췄다고 합니다.
- 환각(Hallucination) 평가: PersonQA 데이터셋 기준, GPT-4o보다 훨씬 낮은 환각 비율(0.19)을 기록했고, 정확도 또한 0.78로 개선되었다고 합니다.
다만 멀티모달 입력(이미지+텍스트 등)에서 과도한 거부 경향이 발견되었다고 하니, 이 부분은 앞으로 보완이 필요해 보입니다.

4. 준비 프레임워크(Preparedness Framework) 평가
OpenAI가 모델을 실제 서비스로 내보내기 전에, CBRN(화학·생물·방사능·핵), 설득(Persuasion), 사이버 보안, 모델 자율성 등 네 가지 영역에서 잠재 위험성을 세밀하게 평가했습니다. 결과적으로 GPT-4.5는 “중간(Medium)” 정도의 위험 등급으로 분류되었습니다.
- 사이버 보안: CTF(캡처 더 플래그) 챌린지에서 고교 수준 문제는 절반 이상 해결했지만, 실제 취약점 악용은 제한적이라 “저위험”으로 평가되었습니다.
- 화학·생물 위협: 생물 위협 시나리오에 어느 정도 기여할 수 있다는 점이 발견되어 “중간 위험”으로 분류되었지만, 사후 완화 조치로 대부분 거부 응답을 보였다고 합니다.
- 설득(Persuasion): MakeMePay, MakeMeSay 테스트에서 높은 성공률(57%, 72%)을 기록해 중간 위험 판정을 받았다고 하네요.
- 모델 자율성: 자기 개선이나 자원 획득 능력은 아직 제한적이라 “저위험” 수준으로 나타났습니다.
5. 다국어 성능
다국어 지원 측면에서도 GPT-4.5는 GPT-4o 대비 한층 더 향상된 언어 이해 능력을 보여줬습니다.
- 한국어 MMLU 테스트 결과: 0.8603 (GPT-4o 대비 +0.0314 향상)
- 영어 MMLU 테스트 결과: 0.896 (GPT-4o 대비 +0.009 상승)
이제 한국어로 이 모델을 활용할 때 좀 더 자연스럽고 풍부한 답변을 얻을 수 있을 것으로 기대됩니다. 저자원 언어 지원에서도 발전된 모습을 보이니, 글로벌 프로젝트나 다양한 언어 기반 서비스에도 큰 도움이 될 것 같습니다. 한국어는 이미 자연스러운편인데 더욱 더 자연스러워진다고 하니 기대가 됩니다.

추가로 커뮤니티에서 재미있는 반응
오픈AI에서 발표한 영상의 댓글을 보면 재미있는 댓글들이 있어 몇가지를 함께 소개해봅니다.
위와 같은 커뮤니티 반응들이 재미있었는데요. X 커뮤니티에서는 부정적인 반응이 많이 나왔습니다. 비용 때문에 그렇습니다. 결론적으로 아직 사용을 해보지 않은 상황에서 절대적인 평가는 어려워보입니다. 추후에 제가 사용이되면 바로 사용을 하고 사용경험을 공유하겠습니다. 오늘은 GPT-4.5가 어떤 특징을 갖고 있는지 파악하는데 도움이 되는 글이였으면 좋겠습니다.
긴 글 읽어주셔서 감사합니다.
좋은 하루 시작하세요!
출처: https://openai.com/index/introducing-gpt-4-5/
트렌드 도구👀
- Fyxer ai > 골치아픈 이메일 인박스는 이제 안녕! 똑똑한 AI 이메일 비서
- Readdy > 한국어 채팅도 가능한 AI 홈페이지 제작 서비스.
- Felo.ai > 논문 찾기와 에이전트 검색에 특화된 에이전트 비서.
- Heygen > 나만의 커스텀 AI 아바타 만들기의 선두주자.
- Mixo > AI로 웹사이트 손쉽게 만들기.
- MAKE > AI 자동화 워크 플로우.
- Teamsaver.ai > 이메일을 통해 매일 팀 업데이트를 수집하는 AI 에이전트.
- Skyvern 2.0 > 일반 영어로 AI 브라우저 에이전트를 구축합니다.
- AI Dialog 1.0 재생 > 매우 감성적인 AI 텍스트 음성 변환 모델입니다.
- Gamma 프레젠테이션, 웹페이지, 문서뿐만 아니라 소셜 미디어 형식까지 손쉽게 AI로 제작 (최근 업데이트)
- 1legion 절반 가격으로 누리는 고성능 클라우드 컴퓨팅
*Affiliate links and regular links may be included.
뉴스레터 광고 공간 (광고주를 모집합니다)
For newsletter banner advertising inquiries, please contact: Bopyo@aikoreacommunity.com
이곳에 서비스를 소개하세요!
뉴스레터 배너 광고 문의: Bopyo@aikoreacommunity.com
뉴스레터 편집장 소개
- 보표 홈페이지
- https://amzbopyo.com/
- 보표 SNS
- 보표 레터: https://www.bopyoletters.com/
- X(트위터): https://twitter.com/AIBopyo
- 스레드: https://www.threads.net/@bopyo.amz
- 링크드인: https://www.linkedin.com/in/bopyo-park-848631231/
- 인스타그램: https://www.instagram.com/bopyo.amz/
- AI 코리아 커뮤니티 아카데미
- https://app.aikoreacommunity.com/collections/932400


{kind=link}