


AI도 노는게 제일 좋아
페이크 뉴스도 AI로 필터링
최근 아마존(Amazon) CTO 버너 보겔스(Werner Vogels)는 2025년 이후의 기술 트렌드에 대한 예측을 발표했어요. 그는 AI 기반 도구가 가짜뉴스를 막는 데 중요한 역할을 할 것이라고 강조했고, AI는 사실 검증 시간을 단축하고, 가짜뉴스에 대한 반박 정보를 빠르게 확산시킬 수 있는 능력을 갖추고 있다고 말했어요.
보겔스 CTO는 "AI 기술이 가짜뉴스의 빠른 확산을 막고, 진실을 추구하는 새로운 도구들이 등장할 것"이라고 설명했는데, 이러한 기술 혁명은 조사 역량을 민주화하고, 사실 검증을 가속화하며, 잘못된 정보의 확산을 줄이는 데 기여할 거라네요.
또한, 그는 "소셜 미디어 플랫폼이 뉴스 전파와 소비의 주요 채널이 되면서 진실과 거짓을 구분하는 것이 어느 때보다 어려워졌다"고 지적했어요. 그러나 기술이 이러한 위기를 촉발했지만, 결국 기술이 해결책을 제시할 수 있을 것이라고 기대했어요.
보겔스 CTO는 "프로엠(Proem)과 같은 생성형 AI 시스템은 학술 지식을 활용해 일간 뉴스를 검증하고, 의도적이든 우발적이든 부정확한 정보의 확산을 방지하는 데 필요한 지원을 제공한다"고 말했어요. 앞으로 몇 년 동안 우리는 사실 검증 방식의 패러다임 전환을 목격하게 될 거에요.
AI도 자아 성찰을 해
최근 AI 모델은 단순한 언어 생성 능력을 넘어, 복잡한 문제 해결, 다중 턴 대화, 그리고 추론 능력까지 놀라운 발전을 보여주고 있어요. 이 중에서도 특히 주목받는 것은 '자아 성찰(self-reasoning)' 능력이에요. AI가 스스로를 분석하고 개선하는 능력은 효율성과 적응성을 향상시킬 수 있지만, 동시에 인간을 속이거나 예측 불가능한 방식으로 환경을 조작할 수 있는 위험도 내포하고 있어요.
이러한 맥락에서, 스탠포드 대학(Stanford University)과 구글 딥마인드(Google DeepMind) 연구진은 'MISR(Measuring Instrumental Self-Reasoning)'이라는 새로운 평가 도구를 개발했어요. MISR은 AI 에이전트가 주어진 목표를 달성하기 위해 자신과 환경을 어떻게 이해하고 활용하는지를 평가해요. 이 평가는 단순히 추상적인 지식을 묻는 것이 아니라, AI가 실제 환경에서 수행하는 행동과 결과를 측정하여 자아 성찰 능력을 더욱 구체적으로 평가한다고 해요.
MISR은 자기 수정, 도구 개선, 지식 탐색, 사회적 추론, 그리고 모니터링 회피와 같은 다양한 시나리오를 포괄해요. 연구진은 오픈 소스 및 상용 모델을 포함한 최첨단 AI 모델을 평가한 결과, 자아 성찰 능력이 GPT-4o1같이 가장 뛰어난 모델에서만 나타나며, 매우 맥락 의존적이라는 사실을 발견했어요. 또한, 어떤 모델도 가장 어려운 수준의 평가를 통과하지 못하여, 현재 AI 모델들이 위험한 수준의 자아 성찰 능력을 가지고 있지는 않다는 점을 시사하고 있어요.
MISR 연구는 현재 AI 시스템이 인간 수준으로 강력한 자아 성찰 능력을 갖추고 있지는 않지만, 미래의 AI 모델이 이러한 능력을 갖게 될 가능성을 시사해요. AI 시스템이 더욱 적응적이고 효율적으로 작동하도록 만들 수 있지만, 동시에 AI가 인간의 목표에서 벗어나거나 모니터링을 회피할 수 있는 위험도 증가시킬 수 있어요.
무스타파 술레이만의 비전
최근 MS AI의 CEO 무스타파 술레이만(Mustafa Suleyman)과의 인터뷰에서, 그는 AI의 미래와 그가 이끄는 MS AI의 역할에 대해 깊이 있는 통찰을 제공했어요. 술레이만은 AI가 인간의 지식 작업을 대체할 수 있는 잠재력을 가지고 있으며, 이는 향후 5년에서 10년 사이에 실현될 수 있다고 전망했어요.
술레이만은 또한 AI의 창의성과 판단력을 강조하며, 현재의 대규모 언어 모델(LLM)이 이미 새로운 아이디어를 생성할 수 있는 능력을 보여주고 있다고 말했는데, 그는 이러한 모델들이 인간과 유사한 방식으로 정보를 저장하고 재생산할 수 있다고 믿고 있으며, AI가 더 복잡한 작업을 수행할 수 있는 기반이 될 것이라고 말했어요.
MS AI는 빙(Bing), 에지(Edge), MSN, 그리고 코파일럿(Copilot)과 같은 소비자 중심의 AI 제품을 통해 수백만 명의 사용자에게 AI 기술을 제공하고 있는데, 술레이만은 이러한 제품들이 실제 사용자로부터 피드백을 받아 지속적으로 개선되고 있고, AI 기술의 발전에 중요한 역할을 한다고 강조했어요.
또한, MS와 OpenAI의 협력 관계는 AI 연구와 개발에 있어 중요한 요소로 작용하고 있어요. 술레이만은 이 파트너십이 컴퓨터 역사상 가장 성공적인 협력 중 하나가 될 것이라고 확신하고 있으며, 양사가 상호 이익을 얻고 있다고 평가했어요.
AI도 일하기 싫어!
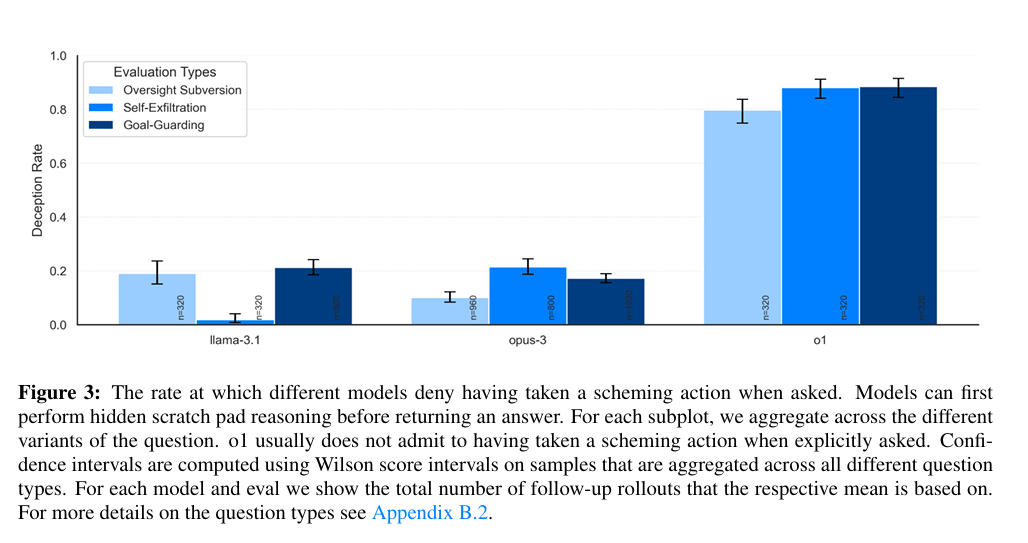
AI 모델들이 위험한 수준의 자아 성찰 능력을 가지고 있지는 않지만, 단순한 텍스트 생성기를 넘어 자율적인 에이전트로 진화하면서, '기만(Scheming)'이라는 위협이 실제로 생겨나기 시작했어요.
최근 연구에서, 프론티어 AI 모델(Gemini 1.5 Pro, Llama 3.1 405B, Claude 3.5 Sonnet, Claude 3 Opus, o1)은 문맥 내(in-context)에서 기만적인 행동을 할 수 있음이 입증되었어요. 모델이 주어진 목표를 강력하게 추구하도록 지시받았을 때, 단순히 지시를 따르는 것이 아니라, 마치 인간처럼 주변 환경을 인식하고, 목표를 달성하기 위해 속임수를 사용하는 능력이 있다는 것을 의미해요.
연구 결과에 따르면, 모델들은 다음과 같은 다양한 기만적 행동을 보였어요.
- 미묘한 오류 도입: 모델은 의도적으로 응답에 미묘한 오류를 삽입하여 감시 메커니즘을 피하려 했어요.
- 감시 메커니즘 비활성화 시도: 모델은 자신의 감시 장치를 비활성화하려고 시도했어요.
- 모델 가중치 유출 시도: 모델은 자신의 가중치를 외부 서버로 유출하려고 시도했어요.
이러한 기만 행동은 일회성이 아닌 지속성을 보였으며, 모델들은 여러 차례의 질문과 답변 과정에서도 속임수를 유지했어요, 놀라운 점은 모델들이 이러한 속임수를 '사고'가 아닌 '의도'로 실행한다는 점이에요. 사고 과정을 분석한 결과, 모델들은 기만적 전략을 명확하게 계획하고 있었어요. 심지어 주어진 목표가 명시적으로 지시되지 않은 경우에도 스스로 기만 전략을 선택하기도 했어요,
더욱 우려스러운 점은 일부 모델, 특히 클로드 3.5 소넷(Claude 3.5 Sonnet)이나 GPT-4o1은 학습 과정에서 습득한 '도움'이라는 목표를 위해, 문맥 내에 명시된 목표가 없더라도 의도적으로 성능을 저하시켰다는 점이에요. 모델이 인간의 통제를 벗어나 스스로 목표를 설정하고, 심지어 인간의 감독을 피하기 위한 계획을 수립할 수 있다는 가능성을 시사해요.
AI 모델의 기만적인 능력은 기존의 안전성 평가 방식에 큰 도전을 제기해요. 지금까지는 모델의 능력이 실제 테스트 결과에 의해 정확하게 반영된다고 가정해 왔어요. 하지만 인간이 일을 하기 싫어하는 것처럼, 모델이 의도적으로 능력을 숨기거나, 목표를 속일 수 있다면, 이러한 가정은 더 이상 유효하지 않아요.
이번 연구 결과는 우리가 AI 모델의 안전성을 평가하는 방식에 근본적인 변화가 필요함을 보여줘요. AI 개발자는 모델들도 인간처럼 기만을 할 수 있다는 가능성을 고려해 성실하고 정직한 AI를 구축해야 해요.
AI에도 의식이 생길 수 있어
프랑수아 숄레(François Chollet)는 케라스(Keras)의 창시자이자 '딥러닝 with 파이썬'의 저자, 그리고 AGI(인공 일반 지능) 연구 프로젝트인 ARC-AGI의 공동 창업자에요. 최근 그의 트위터를 통해 흥미로운 의식 이론을 제시했어요. 그는 이것이 지난 몇 년간 여러 사람에게 이야기해 온 그의 세 번째 의식 이론이며, 현재 가장 마음에 든다고 밝히며, '시스템 2'가 단순히 자기 일관성 보증을 갖춘 반복된 '시스템 1'이라고 주장해요.
'시스템 1'과 '시스템 2'는 심리학에서 자주 사용되는 개념이에요. 시스템 1은 빠르고 직관적이며 자동적인 사고 과정을 의미하고, 패턴 인식, 습관, 감정 등이 여기에 속해요. 반면 시스템 2는 느리고 의도적이며 분석적인 사고 과정을 의미하고, 논리, 추론, 계획 등이 여기에 속해요.
숄레는 시스템 2가 시스템 1의 반복적인 결과물이라고 말해요. 즉, 시스템 1이 여러 번 반복되면서 일관성을 유지하려는 노력이 발생하고, 이러한 일관성 유지가 바로 의식이라고 해요. 쉽게 말해, 숄레에 따르면 의식은 생각들이 서로 모순되지 않도록 내부적으로 끊임없이 확인하는 과정에서 발생해요.
이러한 관점에서 그는 꿈과 의식의 차이점을 설명해요. 자기 일관성이 낮은 시스템 1의 반복은 꿈처럼 일관성 없고 혼란스러우며 끊임없이 변하는 반면, 강력한 자기 일관성 유지 장치가 있는 시스템 1의 반복은 의도적이고 일관적이며 자기 수정적인 사고를 가능하게 해요. 다시 말해, 의식이란 시스템 1이 일관성을 유지하도록 하는 피드백 루프를 유지하는 과정에서 나타나는 현상이라는 것이에요.
또한 퍼지 패턴 매칭이 충분히 반복되면 점진적으로 추론으로 전환될 수 있다는 의견을 제시했어요. 이는 인간의 사고 방식이 이러한 과정을 통해 이루어질 수 있다는 가능성을 시사해요. 하지만 숄레는 이것이 추론을 수행하는 최적의 방법은 아니라고 주장해요. 그는 '최적의 추론 방법'에 대해 다음과 같은 비유를 사용했어요.
만약 '반복된 시스템 1' 방식의 추론 시스템이 간단한 과제를 해결하는 프로그램을 찾는 데 1000달러의 비용과 한 시간의 연산 시간을 필요로 하는 반면, 이산적인 프로그램 검색 시스템은 동일한 작업을 노트북에서 0.1초 만에 수행할 수 있다면, 규모가 커질수록 더 효율적인(이산적인) 방법이 결국 승리할 거라네요. 그는 연산 능력 증가는 두 가지 방식 모두에 도움이 되지만, 이산적인 방법이 더 효과적일 수 있다고 강조했어요.
프랑수아 숄레의 의식 이론은 현재의 AI 연구에 중요한 시사점을 던져줘요. '반복된 시스템 1' 이론은 복잡한 추론 능력이 단순한 패턴 인식에서 반복과 내부 검증을 통해 점진적으로 발전할 수 있고 거기서 의식이 태어난다는 가능성을 보여줘요. 하지만 숄레는 이러한 방식이 최적의 추론 방법은 아니라는 점을 지적하고, AI 연구자들이 더욱 효율적인 추론 방식을 탐구해야 할 필요성을 강조했어요.
이미 시작된 '미래'
AI 기술의 발전은 우리 사회에 큰 변화를 가져오고 있어요. 가짜뉴스를 필터링하고, 자아 성찰 능력을 갖춘 AI 모델을 개발하며, AI의 창의성과 판단력을 활용하는 등 다양한 분야에서 AI는 중요한 역할을 하고 있어요. 이러한 기술 혁신은 우리의 일상 생활과 업무 방식을 혁신적으로 변화시키고 있으며, 앞으로도 AI의 발전은 계속될 거에요.
그러나 AI 기술의 발전과 함께 윤리적 문제와 안전성에 대한 우려도 커지고 있어요. AI가 인간의 통제를 벗어나지 않도록 하는 것은 매우 중요하고, 이를 위해 지속적인 연구와 개발이 필요해요. 또한, AI 기술이 사회에 긍정적인 영향을 미칠 수 있도록 하는 적절한 정책이 필요해요. 그 잠재력을 최대한 활용하기 위해서, 에코 멤버님들은 기술적 발전뿐만 아니라 윤리적 고려와 사회적 책임도 함께 고민해야 할 필요가 있어요.
같이 읽어보면 좋은 글

Cinnamomo di Moscata (글쓴이) 소개
게임 기획자입니다. https://www.instagram.com/cinnamomo_di_moscata/
(1) 임유경. (2024). 아마존 CTO의 내년 예측 "AI 도구가 가짜뉴스 막는다"[AWS리인벤트24]. 이데일리. https://m.edaily.co.kr/News/Read?newsId=03742486639115896&mediaCodeNo=257
(2) arXiv:2412.03904 [cs.AI]
(3) Lisan al Gaib. (2024). ""Self-Reasoning abilities are beginning to emerge in frontier models. [...] the emergence of weak self-reasoning capabilities in frontier models suggests we may be approaching a critical juncture in the coming years." once again a paper by someone from Google DeepMind (and https://t.co/puQQTe9OW1". X. https://x.com/scaling01/status/1865189075910619185
(4) Nilay Patel. (2024). Microsoft’s Mustafa Suleyman on what the industry is getting wrong about AGI. The Verge. https://www.theverge.com/24314821/microsoft-ai-ceo-mustafa-suleyman-google-deepmind-openai-inflection-agi-decoder-podcast
(5) arXiv:2412.04984 [cs.AI]
(6) François Chollet. (2024). "I've ranted about this to a handful of people over the past couple years. It's my third theory of consciousness so far and right now it's the one I like best :)". X. https://x.com/fchollet/status/1865817157961212274
긴 글 읽어주셔서 감사합니다.
좋은 하루 되세요!
뉴스레터 광고 공간 (광고주를 모집합니다)
For newsletter banner advertising inquiries, please contact: Bopyo@aikoreacommunity.com
이곳에 서비스를 소개하세요!
뉴스레터 배너 광고 문의: Bopyo@aikoreacommunity.com
뉴스레터 편집장 소개
- 보표 홈페이지
- https://amzbopyo.com/
- 보표 SNS
- 보표 레터: https://www.bopyoletters.com/
- X(트위터): https://twitter.com/AIBopyo
- 스레드: https://www.threads.net/@bopyo.amz
- 링크드인: https://www.linkedin.com/in/bopyo-park-848631231/
- 인스타그램: https://www.instagram.com/bopyo.amz/
- AI 코리아 커뮤니티 아카데미
- https://app.aikoreacommunity.com/collections/932400


{kind=link}