


AI가 주는 2월의 선물!
OpenAI의 Sora
OpenAI가 이번에는 텍스트로 현실적이고 상상력 풍부한 영상을 생성하는 AI 모델 Sora(소라)를 발표했어요. 소라는 최대 1분까지 영상을 만들 수 있는데, 기술적으로는 DALL E-3(달리 3)의 기술인 확산 트랜스포머(diffusion transformer)라고 부르는 모델을 사용했다고 해요.
소라의 발표에는 많은 사람들이 반응했어요. 샘 알트만(Sam Altman)은 트위터에서 사용자들의 텍스트 입력에 소라로 만든 비디오를 답변으로 보여주었고, 일부 창작 전문가들과 공유하여 피드백을 주고 받았어요.
하지만, 모두가 소라를 좋아하는 것은 아니에요. 일부 사람들은 소라가 물리학을 배우는 것이 아니라, 단지 2D 픽셀을 흉내내는 것이라고 비판했기 때문이에요. 그러나, OpenAI의 연구원인 짐 팬(Jim Fan)은 소라가 실제로 공간과 물리를 이해하면서 영상을 만들어주는 것이라고 주장했는데, 그는 트랜스포머가 하는 일이 결국 텍스트나 이미지나 비디오와 같은 신호를 AI가 알기 쉽게 번역하는 정도에 불과하고 실제 비디오를 생성하는 것은 AI가 직접 배운 것이라고 말했어요.
이런 소라의 성능을 증명하듯, Meta의 AI 연구원인 아르멘 아가잔반(Armen Aghajanvan)은 X에서 이런 거대한 발전을 이룩한 OpenAI 직원들에게 경의를 표하기도 했다고 해요.
비디오를 보고 배우는 인공지능
Meta(메타)에서 이번에 V-JEPA라는 새로운 AI 기술을 발표했어요. 이 기술은 비디오의 일부를 가리고 나머지를 예측하는 방식으로 비디오의 내용을 이해하는 인공지능 모델인데, 메타의 최고 AI 연구원인 얀 르쿤이 제안한 JEPA를 비디오에 맞게 변형한 버전이라고 해요.
V-JEPA는 어떠한 비디오도 보여주기만 하면 스스로 이해하는 자기 지도 학습을 하고, 픽셀 수준의 재구성이 아니라 인간처럼 이 화면이 어떤 '공간'에서 만들어진 것인지 예측을 하기 때문에 성능이 크게 향상될 수 있다고 해요. 이 V-JEPA는 다양한 비디오와 이미지 작업에 적용할 수 있는데, 예를 들어, 동작 분류, 물체 상호작용 인식, 활동 검출 등의 여러 작업에 뛰어난 성능을 보인다고 해요.
하지만, 어디까지나 비디오의 시각적 내용만을 고려한 것이므로, 메타는 여기에 다중 모달 방식으로 오디오 등을 추가하는 것이 다음 단계라고 해요. 또한, 기억력이 늘어나고 더욱 인간과 같이 예측하는 능력을 갖추는 것이 중요한 목표에요. V-JEPA는 AR 안경을 위한 AI 비서와 같은 미래의 응용 분야에 유용할 것으로 기대된다고 해요.
벌써 나온 구글의 신 모델
구글의 새로운 인공지능 모델인 Gemini 1.5(제미나이 1.5)가 나왔다고 해요. 제미나이 1.5는 기존 제미나이 1.0과 달리 다음과 같은 4가지 특징이 있어요.
다중 모달: 텍스트, 이미지, 오디오, 비디오, 코드 등 다양한 정보를 이해할 수 있어요.
장문 이해: 최대 100만 토큰의 긴 문장을 읽을 수 있어요. 책으로는 약 402페이지 정도 된다고 해요.
효율성: Mixture-of-Experts (MoE) 아키텍처를 사용하여 훨씬 가벼우면서 제미나이 울트라만큼 똑똑해요.
책임감과 안전성: 제미나이 1.5는 구글이 추구하는 모토처럼 안전성을 핵심으로 하여 개발되었고, 제미나이 1.5는 사용자의 피드백을 적극적으로 반영할 것이라고 해요.
실제로, 구글 딥마인드(Google DeepMind)의 CEO이자 AI 연구자인 데미스 하사비스(Demis Hassabis)는 무려 402 페이지나 되는 아폴로 11호 책을 AI한테 통째로 학습시킨 다음 간단한 부츠 이미지를 보여주고 여기에 해당하는 닐 암스트롱과 관련된 내용을 말하게 하는데 성공했다고 해요.
AI 코딩인 상식인 구글
구글이 직원들이 더 빠르게 코드를 작성할 수 있도록 돕는 내부 AI 모델인 'Goose’를 사용하고 있다고 해요. 이런 코딩용 내부 AI는 이미 메타에서도 쓰고 있었는데, 구글도 모처럼 큰 마음을 먹고 도입했다고 해요.
Goose(구즈)는 인간의 요청을 파이썬 코드로 변환할 수 있고, 구글은 AI를 테스트하고 개선하기 위해 사용을 권장하고 격려하고 있다고 해요. 메타뿐만 아니라 구글도 이런 것을 보면 조만간 모두가 코딩을 AI한테만 맡기는 시대가 오지 않을까요?
Stable Diffusion보다 우수한
Stability AI가 2월 12일에 Stable Cascade(스테이블 캐스케이드)를 발표했어요. 이 AI는 Stable Diffusion처럼 텍스트로 이미지를 만드는 AI인데, 성능을 높이기 위해 기존보다 구조가 1단계 늘어난 3단 구조를 띄고 있으면서 Würstchen(뷔르스트헨)이라는 신기술을 사용했다고 해요.
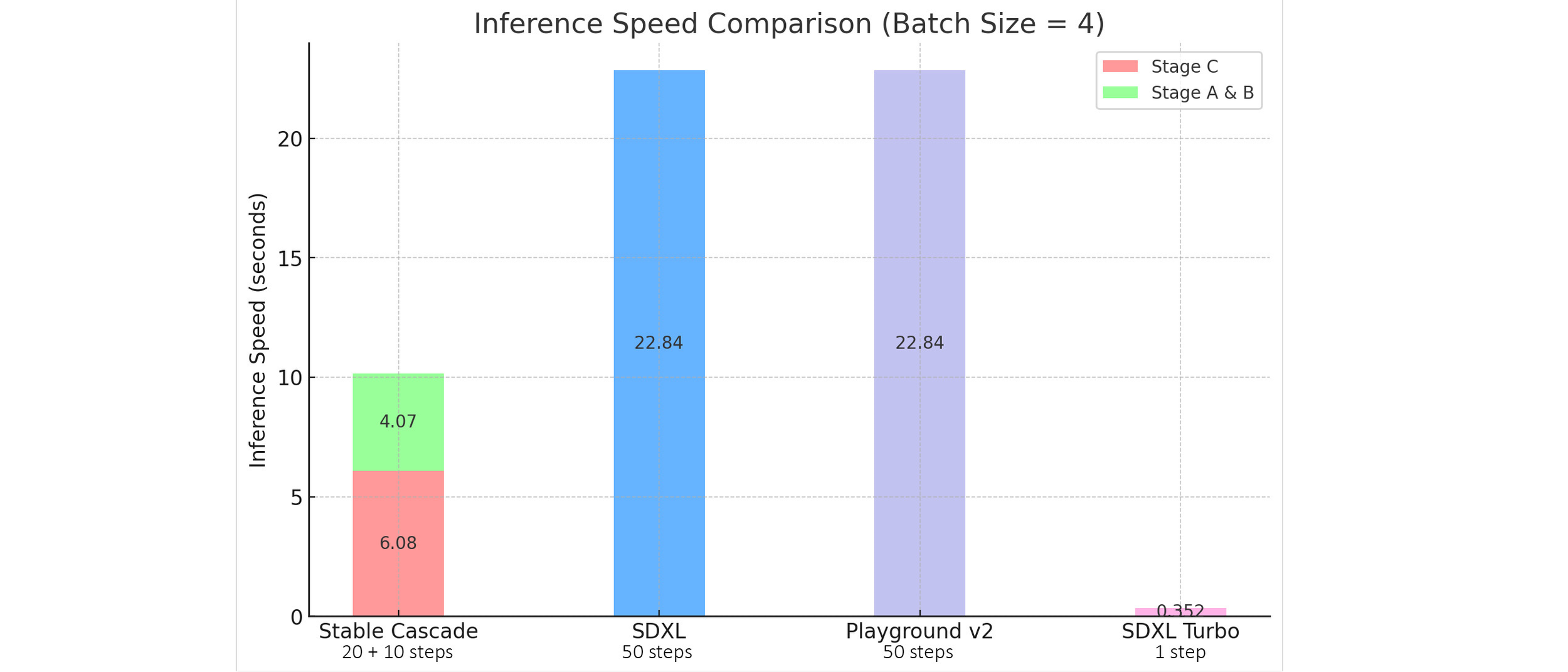
이 모델은 품질, 유연성, 파인튜닝, 효율성 등에서 새로운 기준을 세웠는데, Stability AI의 자체 테스트 결과 SDXL보다 이미지 퀄리티는 높으면서, 만드는 속도는 무려 50%나 줄어들었다고 해요.
기존 Stable Diffusion처럼 스테이블 캐스케이드도 일반적인 텍스트-이미지 생성뿐만 아니라, 이미지 변형, 이미지-이미지 생성 등의 기능도 제공하기 때문에, 적응하는데 무리가 없을거라고 해요.
스테이블 캐스케이드 모델은 아직까지는 비상업적 용도로만 사용할 수 있으며, Stability GitHub 페이지에서 코드와 체크포인트를 다운로드 할 수 있다고 해요.

봄날이 오며
이렇게 2월에도 AI의 발전은 멈추지 않고 끊임없이 인류에게 선물을 주고 있어요. OpenAI, 메타, 구글, Stability AI 등의 기업들은 각자의 방식으로 텍스트, 이미지, 비디오, 코드 등의 다양한 정보를 AI가 이해하고 생성하면서 삶과 일에 많은 도움을 줄 수 있게 세상을 바꾸고 있어요.
AI의 미래는 흥미롭고 도전적이에요. 에코 멤버님들도 지금까지 그래왔듯 AI와 함께 성장하고 협력하면서, 더 나은 세상을 만들어가야 해요.
Cinnamomo di Moscata (글쓴이) 소개
게임 기획자를 준비중입니다. AI 아티스트로도 활동하고 있습니다. Stable Diffusion을 주로 사용합니다. https://www.instagram.com/cinnamomo_di_moscata/
(1) Jim Fan. (2024). "I see some vocal objections: "Sora is not learning physics, it's just manipulating pixels in 2D". I respectfully disagree with this reductionist view. It's similar to saying "GPT-4 doesn't learn coding, it's just sampling strings". Well, what transformers do is just manipulating… https://t.co/6omzD423vr". X. https://twitter.com/DrJimFan/status/175854950058580807
(2) Bindu Reddy. (2024). "OpenAI Shatters The Data Advantage With Sora, OpenAI has proven that there is no inherent advantage to owning a lot of proprietary data. My guess is that they created a lot of synthetic data. Synthetic data generation is extremely common in vision problems, anyway. They built…". X. https://twitter.com/bindureddy/status/1758251081526870176
(3) Armen Aghajanyan. (2024). "I consistently underestimate how far ahead OpenAI is. Huge congrats to the Sora team @_tim_brooks @billpeeb @model_mechanic". X. https://twitter.com/ArmenAgha/status/1758227082986017199
(4) AI at Meta. (2024). V-JEPA: The next step toward Yann LeCun’s vision of advanced machine intelligence (AMI). https://ai.meta.com/blog/v-jepa-yann-lecun-ai-model-video-joint-embedding-predictive-architecture/
(5) Sundar Pichai, Demis Hassabis. (2024). Our next-generation model: Gemini 1.5. Google. https://blog.google/technology/ai/google-gemini-next-generation-model-february-2024/
(6) Demis Hassabis. (2024). "Here’s a fun demo of long-context understanding. First, we asked the model to find 3 amusing moments in the 402-page pdf transcription of the iconic Apollo 11 mission. Then we uploaded a simple drawing of a boot and it identified the moment we had in mind: Neil’s one small step! https://t.co/mx8id3cqSi". X. https://twitter.com/demishassabis/status/175815902771485097
(7) Hugh Langley. (2024). Google quietly launches internal AI model named 'Goose' to help employees write code faster, leaked documents show. Business Insider. https://www.businessinsider.com/google-goose-ai-model-language-ai-coding-2024-2
(8) Anel Islamovic. (2024). Introducing Stable Cascade. Stability AI. https://stability.ai/news/introducing-stable-cascade


{kind=link}