


구글의 AI 메모리를 6배 줄이는 "마법의 압축기" 터보퀀트(TurboQuant)의 등장
이번 주 구글이 공개한 기술 하나가 IT업계를 뒤집어 놓았습니다. 반도체 주가가 일제히 흔들릴 만큼 파급력이 컸는데요. 도대체 어떤 기술이길래 이 난리인지, 일반인도 이해할 수 있게 정리해 봤습니다.
안녕하세요 AI코리아 뉴스레터 구독자 여러분 Sai 김진환입니다. 어제 IT/반도체에서 떠들썩했던 이슈였습니다. 해당 내용에 대해서 AI코리아 뉴스레터에서 쉽게 정리해봤습니다.
AI에게 "기억력"이 왜 중요할까?
ChatGPT나 Gemini와 대화할 때, "아까 말한 거 기억해?"라고 하면 AI가 맥락을 이해하잖아요.
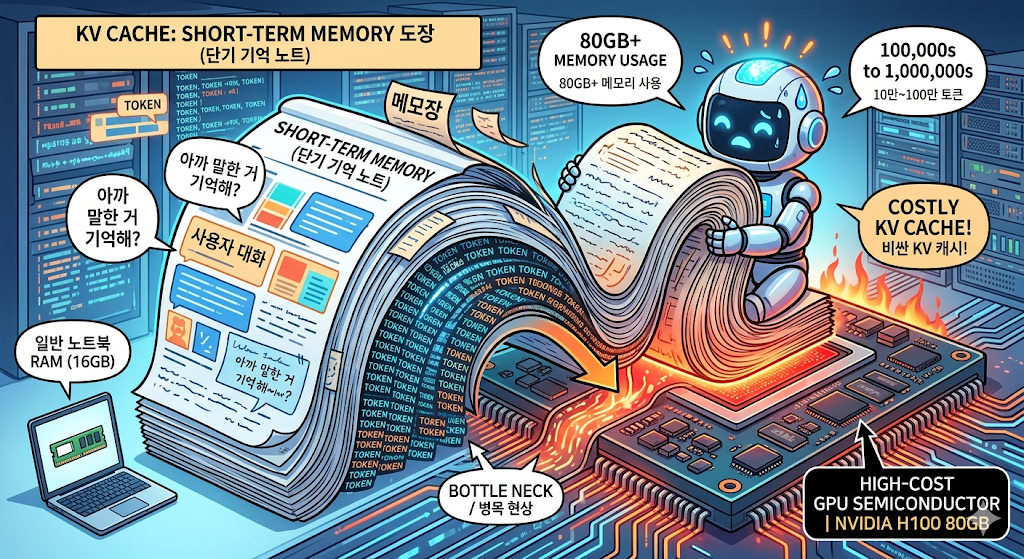
이게 가능한 이유는 AI가 대화 내용을 임시 메모장에 적어두기 때문입니다. 기술 용어로 "KV 캐시"라고 부르는데, 쉽게 말해 AI의 단기 기억 노트입니다.
문제는 이 메모장이 엄청나게 비싸다는 겁니다.
대화가 길어질수록 메모장도 두꺼워지고, 이걸 저장하려면 GPU라는 초고가 반도체의 메모리를 잡아먹습니다. 최신 AI 모델이 긴 대화를 처리하면 이 메모장만으로 80GB를 차지해요. 일반 노트북 RAM이 보통 8~16GB인 걸 생각하면 어마어마한 양이죠.
요즘 AI가 한 번에 처리하는 대화 길이(컨텍스트 윈도우)가 10만, 100만 토큰으로 늘어나면서, 이 메모장 문제는 AI 서비스의 최대 병목이 되어가고 있었습니다.
구글이 만든 TurboQuant, 한마디로 뭔가요?
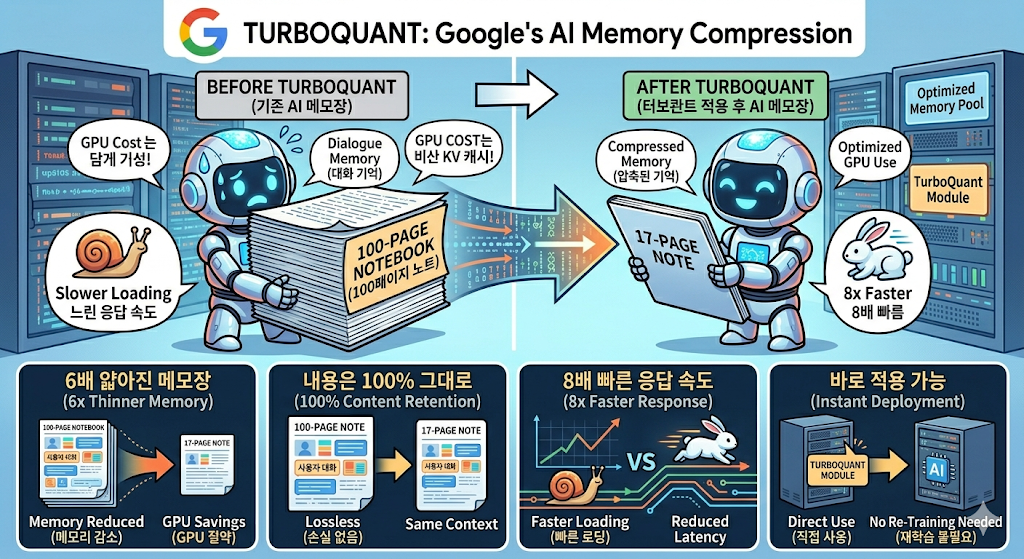
AI의 메모장을 6배 얇게 만들면서도, 내용은 하나도 빠뜨리지 않는 압축 기술
100페이지 노트를 들고 다닌다고 상상해 보세요. 누군가 이걸 17페이지로 줄여주는데, 내용은 100% 그대로인 겁니다. 게다가 이 얇아진 노트를 넘기는 속도도 8배 빨라져요.
더 놀라운 건, AI를 다시 학습시키거나 추가 조정할 필요 없이 그냥 바로 적용할 수 있다는 점입니다.
기존에도 압축 기술은 있었잖아요?
네, 있었습니다. 하지만 항상 같은 문제에 부딪혔어요.
압축은 했는데, "어떻게 압축했는지" 설명하는 부속 메모를 따로 저장해야 해서 실제로는 별로 안 줄었다
이사할 때 옷을 압축팩에 넣었는데, 압축팩마다 "이 팩의 사용법" 설명서를 붙여야 해서 결국 짐이 별로 안 줄어든 것과 비슷합니다. 그리고 너무 세게 압축하면(4비트 이하) AI 답변의 정확도가 눈에 띄게 떨어지는 문제도 있었죠.
TurboQuant는 이걸 어떻게 해결했나?
핵심은 두 단계 조합입니다.
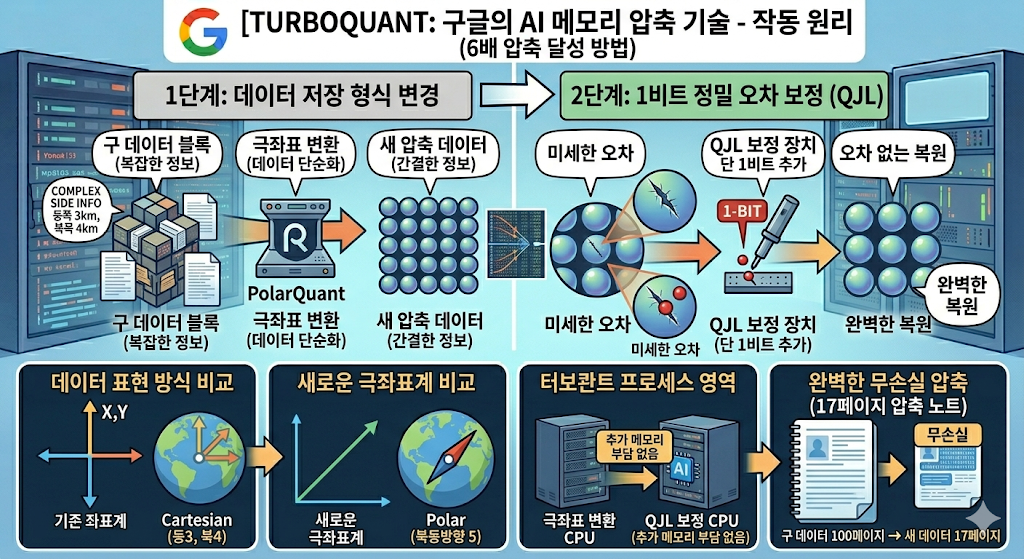
1단계: 저장 형식을 통째로 바꾸기 (PolarQuant)
지도에서 위치를 표시할 때 "동쪽 3km, 북쪽 4km"라고 적는 대신 "북동쪽 방향 5km"라고 적는 것과 비슷해요. 데이터를 극좌표라는 다른 수학적 표현으로 바꿔버리는 건데, 이렇게 하면 기존에 꼭 저장해야 했던 부속 설명서가 아예 필요 없어집니다.
2단계: 미세한 오차를 1비트로 보정 (QJL)
1단계에서 아주 미세한 오차가 생기는데, 이걸 고작 1비트(0 또는 1) 하나로 보정합니다. 추가 메모리 부담이 사실상 제로예요.
쉽게 말해, 부속 설명서 없이도 완벽하게 압축·복원할 수 있는 방법을 수학적으로 찾아낸 것입니다.
실제 성능은?

구글이 NVIDIA 최고급 GPU(H100)에서 테스트한 결과입니다.
📦 메모리 절약 → 기존의 6분의 1로 줄어듦
⚡ 속도 향상 → 핵심 연산이 최대 8배 빨라짐
🎯 정확도 → 3비트까지 압축해도 품질 손실 거의 없음
🔧 추가 작업 → 재학습·미세조정 필요 없음
특히 인상적인 건 "바늘 찾기(Needle-in-a-Haystack)" 테스트입니다. 소설 한 권 분량(10만 단어) 속에 숨겨둔 문장 하나를 찾는 건데, 압축 후에도 100% 정확하게 찾아냈습니다. 즉, 메모장을 6배 줄여도 AI의 기억력은 전혀 손상되지 않았다는 뜻입니다.
이게 왜 중요한 건데?
이 기술이 실제로 적용되면, 크게 세 가지가 달라집니다.
1. AI 운영 비용이 크게 줄어든다
같은 GPU로 훨씬 더 긴 대화를 처리할 수 있고, 더 많은 사용자를 동시에 서비스할 수 있습니다. AI 기업 입장에서는 서버 비용이 극적으로 절감됩니다.
2. 스마트폰에서도 똑똑한 AI를 돌릴 수 있다
메모리가 적은 기기에서도 긴 맥락의 AI를 구동할 수 있게 됩니다. 3만 토큰 이상의 대화를 스마트폰에서 처리하는 것이 현실적으로 가능해지는 거죠. 고성능 AI가 클라우드를 거치지 않고 내 손 안에서 돌아가는 시대가 가까워집니다.
3. AI 검색이 더 빠르고 정확해진다
TurboQuant는 대화 메모장뿐 아니라 벡터 검색(의미 기반 검색)에도 적용됩니다. 수십억 개의 문서를 "의미"로 비교하는 검색이 더 빠르고, 더 적은 메모리로 가능해집니다.
그래서 사람들이 왜 이렇게 난리인 거야?
IT업계가 들썩인 데는 두 가지 이유가 있습니다.
첫째, 기술 자체의 파급력. Cloudflare CEO Matthew Prince는 이걸 "구글의 DeepSeek 모먼트"라고 불렀습니다. 지난해 DeepSeek이 "저비용 고성능 AI"로 업계를 뒤흔든 것처럼, TurboQuant도 AI 효율성의 판을 바꿀 수 있다는 의미입니다. 인터넷에서는 HBO 드라마 「실리콘밸리」에 나온 가상의 무손실 압축 기술 "Pied Piper"에 빗대며 열광했고, 구글 발표 트윗은 24시간 만에 1,190만 뷰를 기록했습니다.
둘째, 반도체 시장에 대한 충격. "메모리가 6분의 1만 있어도 된다면, 메모리 반도체 수요가 줄어드는 것 아니냐"는 우려가 퍼지면서 삼성전자, SK하이닉스를 비롯한 글로벌 메모리 주가가 하루 만에 급락했습니다.
다만 이 우려에 대해서는 반론도 만만치 않습니다. TurboQuant가 압축하는 건 대화 중 생기는 "임시 메모"뿐이고, AI 모델 자체의 크기나 학습에 필요한 메모리에는 영향이 없기 때문입니다. 또한 역사적으로 기술 효율이 좋아지면 총 수요는 오히려 늘어왔습니다. 자동차 연비가 좋아졌다고 운전을 덜 하지는 않는 것처럼요.
알아둬야 할 한계점
⚠️ 아직 연구 단계
공식 코드 공개는 2026년 2분기 예정이고, 현재는 논문만 존재합니다. llama.cpp 등 오픈소스 커뮤니티에서 구현체가 나오고 있지만, 아직 실제 서비스에 쓸 수준은 아닙니다.
⚠️ 소규모 모델에서만 검증
테스트에 쓰인 모델이 70~80억 파라미터급(Gemma, Mistral, Llama-3.1-8B)입니다. 실제 서비스에 쓰이는 700억~4,050억 파라미터 모델에서는 아직 검증이 안 됐습니다.
⚠️ 완전히 새로운 기술은 아님
TurboQuant 논문은 2025년 4월에 이미 공개되었고, 이번에 구글이 블로그 포스트와 ICLR 2026 학회(4월, 브라질) 발표를 통해 다시 조명한 것입니다.
정리
뭘 만들었나 → AI 메모장(KV 캐시)을 6배 압축하는 소프트웨어 기술
뭐가 대단한가 → 품질 손실 제로, 속도 8배 향상, 재학습 불필요
어디에 쓰이나 → AI 추론 비용 절감, 모바일 AI, 벡터 검색 고속화
지금 바로 쓸 수 있나 → 아직 아님. 코드 공개 Q2 예상, 대형 모델 검증 미완
핵심 원리 → 좌표 변환(PolarQuant) + 1비트 보정(QJL)으로 부속 정보 없이 압축
AI가 더 싸고, 더 빠르고, 더 가볍게 작동하는 시대. TurboQuant는 그 방향으로 가는 중요한 이정표가 될 수 있습니다.
오늘의 용어 사전
| 어려운 말 | 쉬운 말 |
|---|---|
| KV 캐시 | AI가 대화 내용을 적어두는 임시 메모장 |
| 양자화 | 데이터를 더 작은 크기로 압축하는 것 |
| 추론(Inference) | AI가 학습을 마친 후 실제로 답변을 생성하는 과정 |
| 컨텍스트 윈도우 | AI가 한 번에 기억할 수 있는 대화의 길이 |
| 벡터 검색 | 키워드가 아니라 "의미"로 문서를 찾는 검색 방식 |
| ICLR 2026 | 4월에 열리는 세계적 AI 학회 (TurboQuant 정식 발표 예정) |
[저자 관련 정보]
이름 : 김진환
소속: 주식회사 위니브 데이터 Lead - https://weniv.co.kr/
데이터 커뮤니티 공식 블로그 - https://www.dayliter.ai.kr/
고려대학교 빅데이터사이언스학부 데이터 강의, 경제통계학 박사수료
데이터 분석 강의 문의 및 생성형 AI 강의 문의도 언제든 환영입니다.
문의 : 이메일 주소: happydata1510@gmail.com
%EC%9D%98%20%EB%93%B1%EC%9E%A5){kind=link}