

AI는 이미지를 어떻게 생성할까? (Feat. AI Art의 현주소)
안녕하세요. 부루퉁입니다.
생성형 AI에 관심을 두고 뉴스레터를 써온 지도 어느덧 1년이 넘었습니다. 처음에는 2022년 10월, 챗GPT가 등장하고 NAI를 이용해 이미지를 만들어보면서 AI에 흥미를 갖게 되었습니다. 23년부터는 AI 전문 블로그를 운영하며, 공부한 지식과 정보를 꾸준히 공유하고 있습니다. 그러다 23년 11월, 보표님의 권유로 AI 코리아 커뮤니티에서 첫 뉴스레터를 발행했는데, 그때 다뤘던 내용이 바로 'Meta의 영상 제작 AI Emu Video'였습니다. 글을 쓰는 방식으로 AI 소식을 전한 지 이렇게 오래됐다는 게 새삼 신기하네요.

2024년에는 본격적으로 AI Art 분야에 뛰어들어, AI 아티스트로 데뷔했습니다. 1년 동안 전시회에 9번 참여하고, 제 작품을 판매하기도 했는데요. 그 과정에서 여러 AI 아티스트들과 교류했고, 순수예술 작가님들이 AI Art와 생성형 AI를 어떻게 바라보는지 직접 들어볼 수 있었습니다. 그래서 오늘은 국내 AI Art의 흐름과 함께, 이미지 생성 AI의 기본 원리에 대해 제 나름대로 정리해보려 합니다.
AI Art의 현주소

챗GPT와 함께 이미지 생성 AI(Midjourney, SD, Flux 등)가 처음 공개됐을 때, 세상이 크게 술렁였습니다. 인공지능 분야에 종사하는 분들이나 일반인들 모두, 창작의 영역이 이렇게 빠르게 AI에 의해 재편될 거라고는 상상하지 못했기 때문이죠. 그래서 초창기에는 전 세계적으로 부정적인 시선이 많았습니다. “이건 진짜 예술이 아니다.”, “단순 모방이다.”, “남의 그림을 훔쳐 배운 것.”라는 말들을 자주 들을 수 있었죠.
하지만 요즘 들어서는 순수예술을 하시는 분들조차도 AI Art에 대한 생각이 많이 바뀌었습니다. 물론 아직도 반대하시는 분들이 적지 않지만, AI Art를 새로운 창작 영역으로 인정하고, 전통 예술과는 별개로 디지털 아트만의 가능성을 눈여겨 보는 분들도 많아졌습니다. 실제로 생성형 AI를 직접 배우려는 작가님들도 점점 늘고 있습니다.

그동안 전통 미술에만 집중해온 갤러리들도 AI Art의 시장성과 가능성을 눈여겨보기 시작했습니다. 그래서 AI 아티스트와 함께 단체전, 개인전을 여는 사례가 하나둘씩 늘고 있는데요. 최근 인사동에서 개인전을 진행한 '태정AI 오용택' 작가님이 대표적인 예라고 할 수 있겠습니다.
점차 더 많은 예술가와 갤러리가 AI Art를 받아들이고 있는 걸 보면, 이제 AI Art는 단순한 유행이 아니라 예술의 한 갈래로 자리매김해 가는 모습입니다. 앞으로 어떤 새로운 작품들이 등장할지 기대가 큽니다.
이미지 생성 AI는 어떻게 이미지를 생성할까?
1년 동안 AI 아티스트로 활동하면서 가장 많이 들었던 질문이자, 동시에 답변하기 까다로운 질문입니다. 저 역시 이미지 생성 AI의 원리에 대해 딱 부러지게 설명할 수 있는 분들이 많지 않다고 생각해왔는데요. 그래서 이번 글에서는 제가 아는 한도 내에서 최대한 쉽게 정리해보겠습니다.

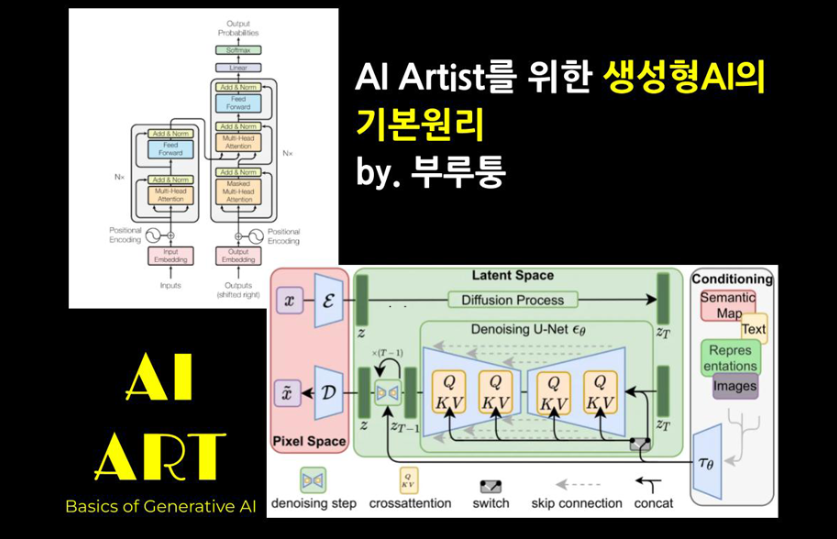
이미지 생성 AI로는 Midjourney, Stable Diffusion, Flux, DALL-E 등이 대표적이죠. 이들은 크게 Diffusion과 CLIP 같은 기술을 기반으로 작동합니다. 그런데 이 두 기술을 알기 전에, 이 모델들이 대체로 LLM(Large Language Model)과 어떤 공통점을 갖는지도 알아두면 이해에 도움이 됩니다. 결론부터 말씀드리면, 텍스트를 분석할 때 Transformer라는 메커니즘을 쓴다는 점입니다.
LLM과 Transformer
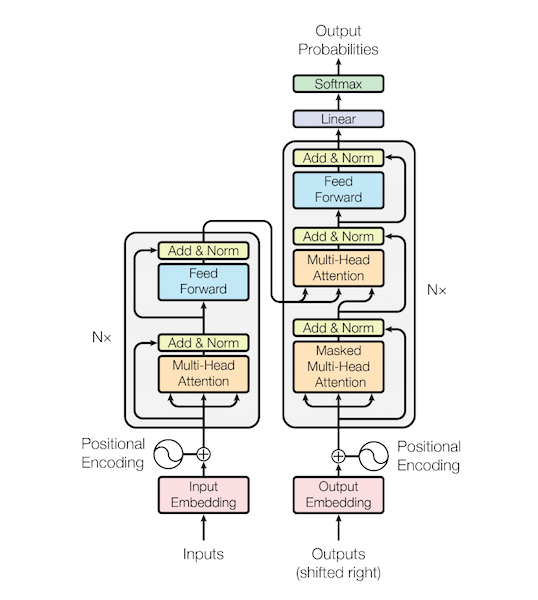
LLM은 대규모 텍스트 데이터를 학습해, 사람이 쓰는 언어를 이해하고 생성하는 모델입니다. 대표적으로 ChatGPT, Claude, Gemini 등이 있죠. 이 모델들이 공통으로 활용하는 게 바로 Transformer라는 구조입니다.
Transformer의 핵심은 Self-Attention(집중)으로, 문장 안에서 중요한 단어나 정보에 집중하고, 서로의 관계를 파악합니다. 예를 들어 “나는 오늘 배를 타고 제주도에 갔다.”라는 문장이 있다면, ‘나는’, ‘배’, ‘타고’, ‘제주도’와 같은 단어가 서로 어떻게 연결되는지 여러 각도에서 살펴보며, 다음에 올 단어를 추론해내는 식이죠.
이미지 생성 AI와 Transformer, 그리고 Diffusion

그렇다면 이미지 생성 AI와 LLM은 무엇이 비슷할까요? 둘 다 대규모 데이터에서 패턴을 학습한다는 점, 그리고 Transformer 구조를 활용해 텍스트를 이해한다는 점이 닮았습니다.
- 예를 들어, CLIP 같은 텍스트 인코더 부분에서 Transformer가 활용돼, “어떤 이미지를 만들어야 하는지”를 분석합니다.
하지만 이미지를 실제로 만들어내는 핵심 단계는 조금 다릅니다.
- 우리가 흔히 말하는 Diffusion 모델은 U-Net이라는 구조를 중심으로 작동합니다. 여기서도 Attention 기법이 쓰이긴 하지만, LLM에서 사용하는 Transformer와는 약간 다른 방식이라고 할 수 있습니다.
- 쉽게 말해, Transformer는 “이 문장을 어떻게 이해하고 표현해야 하지?”라는 문제를 해결하고, Diffusion(U-Net)은 “그렇다면 어떤 픽셀들을 어떻게 채워 넣어 이미지를 만들지?”를 담당한다고 보시면 됩니다.
결국 이미지 생성 AI도 "텍스트를 이해하는 단계”와 “이미지를 합성·생성하는 단계”로 나눌 수 있습니다. 텍스트 이해 단계에서 Transformer가 활약하고, 실제 이미지를 그리는 단계에서는 Diffusion 모델(U-Net + Attention)이 핵심 역할을 맡습니다.
정리하자면, 이미지 생성 AI는 텍스트(프롬프트)를 Transformer 기반 모델로 해석한 뒤, Diffusion(주로 U-Net) 구조를 통해 하나하나 픽셀을 채워 나가며 이미지를 완성합니다. 즉, “문장을 이해하는 단계”와 “이미지를 만들어내는 단계”가 결합된 결과물이라고 볼 수 있습니다.
결론적으로, 이미지 생성 AI는 어떻게 이미지를 생성하는가?에 대한 답변은 다음과 같습니다. "AI가 텍스트를 보고 어떤 이미지를 만들어야 하는지 생각한 뒤, 실제 그림을 그려내는 두 단계를 결합해 이미지를 생성합니다."
그럼 Diffusion과 CLIP에 대한 자세한 이야기는 다음 뉴스레터에서 이어가도록 하겠습니다. 감사합니다.
부루퉁 인스타그램: https://www.instagram.com/boorutung/
부루퉁의AI 네이버 블로그: https://blog.naver.com/ldlquddnr
부루퉁의 업데이트되는 챗GPT 전자책: https://vo.la/blbLY
뉴스레터 광고 공간 (광고주를 모집합니다)
For newsletter banner advertising inquiries, please contact: Bopyo@aikoreacommunity.com
이곳에 서비스를 소개하세요!
뉴스레터 배너 광고 문의: Bopyo@aikoreacommunity.com
뉴스레터 편집장 소개
- 보표 홈페이지
- https://amzbopyo.com/
- 보표 SNS
- 보표 레터: https://www.bopyoletters.com/
- X(트위터): https://twitter.com/AIBopyo
- 스레드: https://www.threads.net/@bopyo.amz
- 링크드인: https://www.linkedin.com/in/bopyo-park-848631231/
- 인스타그램: https://www.instagram.com/bopyo.amz/
- AI 코리아 커뮤니티 아카데미
- https://app.aikoreacommunity.com/collections/932400


){kind=link}