

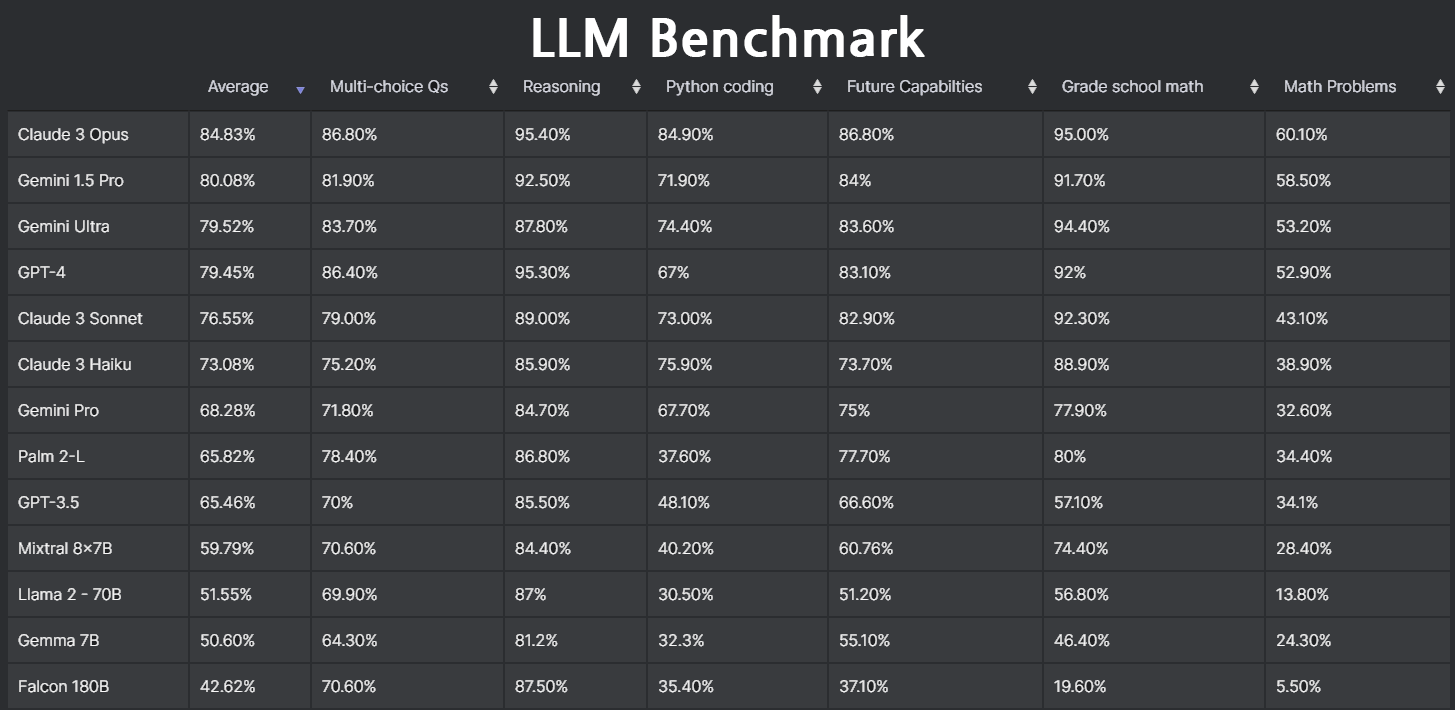
LLM(언어모델) Benchmark 항목, 용어 정리
GPT-4의 등장부터 Claude3, Gemini, LLaMa3까지 다양한 생성형 언어모델이 등장할 때마다 MMLU, GPQA, DROP 등 알기어려운 용어의 항목에 점수가 매겨집니다. 이 점수를 통해 LLM(언어모델)이 어떻게 뛰어난지, 어떤 LLM을 능가했는지, 어떤부분에서 강점을 보여주는지 알 수 있습니다.
컴퓨터의 CPU, GPU 성능에 대한 벤치마크 랭킹을 확인하듯, 앞으로는 인공지능에 대한 벤치마크도 더 자주 접하게 될텐데요. 오늘은 각 벤치마크 항목과 용어에 대해 자세히 살펴보는 시간을 가져보겠습니다.
LLM(언어모델) Benchmark 항목 해석

최근에 공개된 Meta의 LLaMa3 Benchmark입니다. 이 표를 어떻게 해석해야하는지 하나씩 함께 살펴보겠습니다. 먼저 Pre-Trained와 Instruct는 모델의 두 가지 다른 설정에 대한 성능을 나타냅니다.
Pre-trained는 미리 학습된 내용을 바탕으로 하며, 특정 작업에 대한 사전 지식이나 추가적인 지시 없이 테스트를 실행합니다. Instruct는 모델에게 특정 지시를 제공해 문제를 해결하도록하는 경우를 말합니다. 이제 각 항목에 대해 알아보겠습니다.
MMLU: 다양한 주제에 대한 언어 이해력을 평가합니다. 하단의 5-shot은 AI가 실제 문제를 보기 전에 5개의 관련 예제를 본다는 것을 뜻합니다.
AGIEval English: 모델이 실제 인간이 마주하는 복잡한 상황에서 어떻게 작동하는지 평가하는 항목입니다. 대학 입학 시험, 법률, 과학 등 여러 분야에서 전문화된 시험 문제를 포함하고 있습니다.
BIG-Bench Hard: 언어 기반 문제를 해결함으로써 AI의 추론 능력을 평가하며, 언어모델이 얼마나 발전했는지 어떤 부분에서 인간을 뛰어넘을 수 있는지 평가합니다. 하단에 표기된 CoT는 Chain of Thought로 AI가 도출한 결과에 대한 추론 과정을 명시하도록 합니다.
ARC-Challenge: 과학적 추론 능력을 평가하는 테스트입니다. 25-shot은 AI가 많은 예제를 본 후 테스트를 진행했다는 것을 나타냅니다. 복잡한 문제에 대한 이해도를 평가합니다.
DROP(Discrete Reasoning Over Paragraphs): 문단을 이해하고, 문단 안의 정보를 기반으로 복잡한 질문에 대답하는 능력을 평가합니다. 3-shot, F1은 3개의 예제를 본 후 F1 점수를 통해 평가받았다는 뜻입니다.
GPQA(General Purpose Question Answering): AI의 일반적인 질문에 대한 답변 능력을 평가합니다. 0-shot은 예제 없이 문제에 접근했다는 것을 뜻합니다.
HumanEval: AI의코딩 문제, 프로그래밍 문제를 해결하는 능력을 평가합니다.
GSM-8K(Grade School Math 8K): 초등 수준의 수학 능력을 평가하는 항목입니다. 8-shot, CoT는 AI가 예제를 보고 추론과정을 통해 문제를 풀었다는 것을 나타냅니다.
MATH: 더 복잡한 수학 문제 풀이에 대한 능력을 평가합니다. 현재 GPT-4 Turbo 0409 업데이트 모델이 인정받고, 높은 점수를 딴 항목입니다.
모든 항목에 대한 점수를 놓고 Meta LLaMa3 400B+ 모델에 대한 평가를 하면, 좌측 Pre-trained 설정 모델은 다양한 주제에 대한 언어 이해력이 84.8%이며, 문단 이해, 과학적 추론, 어려운 과제들을 해결하는데 높은 점수를 받았습니다. 다만 실제 인간이 마주하는 복잡한 상황에 대해서는 다소 약한 모습을 보였습니다.
우측 Instruct 설정 모델은 Pre-trained 설정보다 다양한 주제에 대한 언어 이해력과 프로그래밍 문제에서 좀 더 높은 점수를 받았고, 초등수학의 추론과정 점수는 매우 높습니다. 하지만 예시 없이 접근한 일반적인 질문과 복잡한 수학 문제에서 낮은 점수를 기록했습니다. 정도로 해석할 수 있습니다.
다소 복잡하고, 지루한 내용이었습니다만, AI에 관심이 많은 에코커뮤니티 여러분께서 AI 벤치마크를 직접 해석하고, 본인의 상황에 알맞게 사용할 수 있는 가성비있는 모델을 직접 선별할 수 있기 바랍니다.
부루퉁의AI 네이버 블로그: https://blog.naver.com/ldlquddnr
부루퉁의 업데이트되는 챗GPT 전자책: https://vo.la/blbLY
Introduce your service here!
For newsletter banner advertising inquiries, please contact: Bopyo@aikoreacommunity.com
이곳에 서비스를 소개하세요!
뉴스레터 배너 광고 문의: Bopyo@aikoreacommunity.com


%20Benchmark%20%ED%95%AD%EB%AA%A9%2C%20%EC%9A%A9%EC%96%B4%20%EC%A0%95%EB%A6%AC){kind=link}