


메타 얀 르쿤 "AGI 도약 아키텍처 '제파(JEPA)' 개발 중" 트랜스포머와 제파의 차이점

현재 메타의 수석 AI 과학자 얀 르쿤이 AI를 도약시킬 아키텍쳐 '제파'를 개발 중이라고 밝혔습니다. 얀 르쿤은 인공지능 분야, 딥 러닝과 컴퓨터 비전 분야의 선구자로, GPT 모델과 같은 대규모 언어 모델은 '지능을 가진 것처럼 보이는 단순한 패턴 인식기'라고 비판했던 인물입니다.
얀 르쿤은 '현재 LLM 모델에 사용되는 트랜스포머 방식은 학습한 지식을 확률적으로 출력하는 방식으로 실제 생각, 계획 없이 한 단어씩 차례로 생성하는 구조'라 설명했습니다. 이어 '복잡한 질문과 정보를 장시간 유지하는 것이 어렵기 때문에 여전히 어리석은 실수를 저지른다.'라고 지적했습니다.
반면 '제파(JEPA)'는 학습한 내용을 확률적으로 출력하는 방식이 아닌, 추론하고 계획하는 방법으로, AGI 개발에도 연결된다고 강조했습니다. 메타의 CEO 마크 주커버그도 올해부터 AGI 개발이 목표라고 밝혔습니다.
'제파(JEPA)'와 '트랜스포머(Transformer)'의 차이점
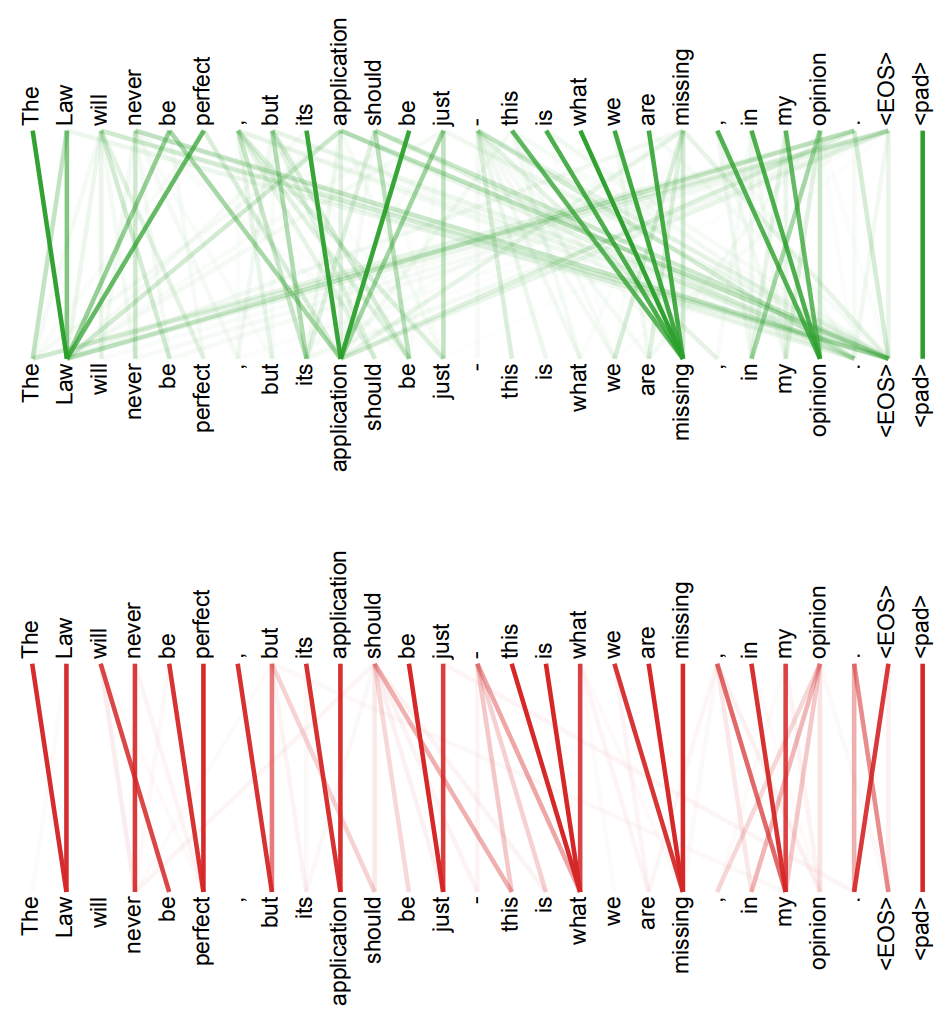
Trnasformer는 Self-attention을 통해 문장 속에서 각 단어가 서로 어떻게 연관되어 있는지 파악하고, 분석합니다. 그리고 문장에 알맞는 단어로 답변을 하는 방식입니다.
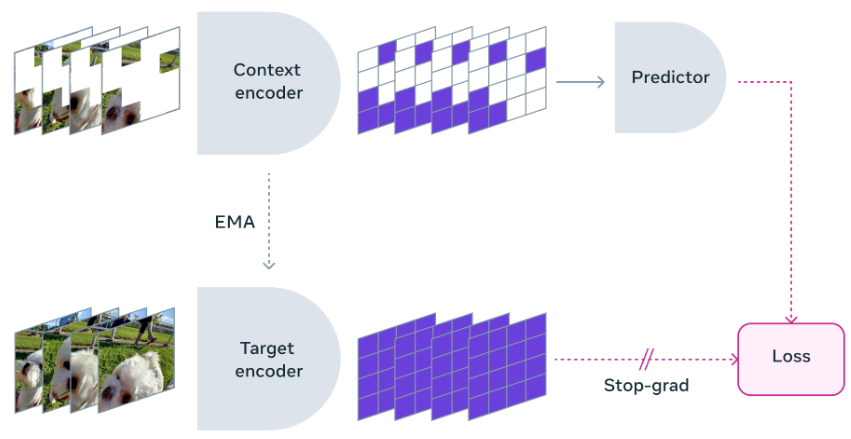
Meta에서 공개한 제파는 현재 V-Jepa(비디오 특화 모델) 모델이지만 추론 방식은 동일 하기에 해당 내용으로 설명하도록 하겠습니다. 위 이미지를 보면 V-JEPA는 비디오에서 빠진 부분이나 가려진 부분을 예측하는 방식으로 학습하는 비생성 모델인 것을 알 수 있습니다.
V-JEPA는 예측하기 어려운 정보는 버릴 수 있는 유연성을 갖고 있어, 학습 효율과 샘플 효율을 1.5배에서 6배까지 향상시킬 수 있습니다. V-JEPA는 자기주도 학습을 사용해 레이블(데이터에 붙어 있는 태그나 이름)이 없는 데이터만으로 사전 훈련됩니다. V-JEPA에서는 비디오의 큰 부분을 가려 모델이 조금만 볼 수 있도록 하고, 예측기에게 실제 픽셀이 아닌, 공간에서 빠진 부분을 채우도록 요청해 비디오의 내용을 더 깊이 이해하며 학습하도록 합니다.
얀 르쿤이 비판해 온 현시점의 LLM 모델을 뛰어넘을 수 있을지, AGI 개발을 앞당길 수 있을지 기대되는 새로운 아키텍처 JEPA에 대한 소식이었습니다.
Meta V-JEPA: https://ai.meta.com/blog/v-jepa-yann-lecun-ai-model-video-joint-embedding-predictive-architecture/
부루퉁의AI 네이버 블로그: https://blog.naver.com/ldlquddnr
부루퉁의 업데이트되는 챗GPT 전자책: https://vo.la/blbLY


'%20%EA%B0%9C%EB%B0%9C%20%EC%A4%91%22%20%ED%8A%B8%EB%9E%9C%EC%8A%A4%ED%8F%AC%EB%A8%B8%EC%99%80%20%EC%A0%9C%ED%8C%8C%EC%9D%98%20%EC%B0%A8%EC%9D%B4%EC%A0%90){kind=link}