


상상은 현실이 된다
영원한 적은 없다!
AI 산업이 사상 최대 규모의 저작권 집단소송이라는 거대한 파도에 또다시 직면했어요. 앤트로픽 AI(Anthropic AI)를 상대로 제기된 이 소송은 잠재적 원고가 최대 700만 명에 달하는데다, 패소 시 발생할 천문학적인 배상액은 개별 기업을 넘어 AI 산업 전체를 재정적으로 파멸시킬 수 있다는 경고가 나오고 있거든요.
앤트로픽과 주요 기술 산업 협회들은 이 소송을 방관한다면, 미국의 AI 기술 경쟁력과 산업의 미래를 뒤흔드는 중대한 위협이라고 주장하고 있어요. 이들의 핵심 논리는 소송 규모가 낳는 '강압적인 합의 압력'이에요. 수천억 달러에 이를 수 있는 잠재적 책임 앞에서, 기업은 AI 학습의 정당성을 법정에서 다투기보다 파산을 피하기 위해 합의를 선택할 수밖에 없거든요. AI 학습과 저작권의 관계에 대한 중요한 법적 선례를 남기지 못한 채, 막대한 비용 지불이라는 결과만 낳을 수 있어요. 업계는 법원이 소송의 파급력을 제대로 분석하지 않고 성급하게 집단소송을 인증했다고 비판하며 항소로 제동을 시도하고 있어요.
그러나 이 결정에 반대하는 것은 신기하게도 AI 업계뿐만이 아니에요. 역설적으로 저자 단체, 전자 프런티어 재단(EFF), 도서관 협회 등 권리자들을 대변하는 단체들도 집단소송 인증에 우려를 표하고 있어요. 이들은 저작권 소송이 본질적으로 집단소송에 부적합하다고 지적했는데, 각 저작물의 소유권 증명은 매우 복잡한 문제이기 때문이라네요. 파산한 출판사, 공동 저자, 사망한 작가의 분할된 권리, 주인을 알 수 없는 '고아 저작물' 등 수많은 변수가 존재하는 상황에서, 법원이 이 복잡성을 간과한 채 수백만 건을 하나의 소송으로 묶으려 하는 것은 현실을 무시한 처사라고 말이죠.
결국 서로 대립되는 AI 업계와 저자 권익 단체는 이유는 달라도 같은 편에 서게 되었어요. 이 성급한 집단소송은 AI와 저작권의 핵심 법적 쟁점을 해결하지 못하고, 불확실성만 남기는 '사망 선고'가 될 수도 있어요. 한쪽은 산업의 존립을, 다른 한쪽은 권리의 정당한 해결을 원하지만, 현재의 소송 형태는 양측 모두에게 최악의 시나리오로 향하고 있어요. 이 거대한 소송의 향방이 AI와 창작의 미래에 중대한 분수령이 될 것 같아요.
뿌리부터 입맛대로
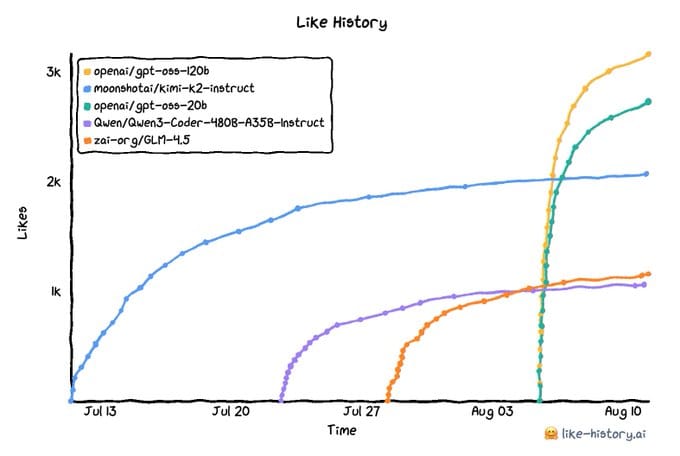
공개 직후부터 폭발적인 반응을 얻은 GPT-OSS는 기존 모델들의 인기를 단숨에 뛰어넘는 기염을 토했어요. 소셜 미디어와 허깅페이스(Hugging Face) 데이터를 분석한 그래프를 보면, 후발주자임에도 불구하고 가파른 상승세로 단기간에 '올해 가장 많은 '좋아요'를 받은 모델'의 자리를 차지했거든요. 출시 초기부터 500만 건 이상의 다운로드와 400개가 넘는 파인튜닝(미세조정) 모델이 파생되는 등, 그 인기는 단순한 수치를 넘어 하나의 현상으로 자리 잡았어요.
더욱 흥미로운 점은 GPT-OSS의 기술적 본질에 대한 새로운 발견이에요. OpenAI는 이 모델을 특정 작업, 즉 '추론 전용'으로 공개했어요. 범용적인 활용보다는 특정 기능에 초점을 맞춘 제한적인 모델임을 강조했거든요. 하지만 코넬 대학(Cornell University)과 메타(Meta) AI의 연구원 잭 모리스(Jack Morris)를 비롯한 개발자들은 이 추론 전용 모델의 이면에 강력한 '순수 베이스 모델(base model)'이 숨어있다는 사실을 밝혀냈어요.
그들은 분석을 통해 gpt-oss-20b-base와 같이 추출된 베이스 모델을 공개하면서, 또 다른 파장을 일으켰어요. 제한된 기능의 모델에서 완전한 잠재력을 가진 범용 모델을 '추출'해냈다는 사실은 오픈소스 커뮤니티의 집단 지성과 기술적 역량을 여실히 보여주는 사례라고 하네요.
이번 GPT-OSS 열풍과 베이스 모델의 발견은 단순히 인기 있는 모델의 등장을 넘어, 오픈소스 커뮤니티가 모델을 어떻게 확장하고 재창조할 수 있는지 보여주는 중요한 이정표가 될 거에요.
수술하는 법을 까먹었어
2025년 8월, AI가 의료계에 던진 화두는 그 어느 때보다 극명한 양면성을 드러내고 있어요. 한쪽에서는 GPT-5 Pro가 인간 명의(名醫) 수십 명을 합친 듯한 초월적 진단 능력을 선보이는가 하면, 다른 한쪽에서는 AI에 의존한 의사의 술기(術技)가 퇴화한다는 충격적인 연구 결과가 발표되었거든요.
최근 텍사스의 한 응급의학과 의사는 페이스북 의사 그룹에서도 해결하지 못한 복잡한 사례 두 건을 'GPT-5 Pro'를 통해 해결했다고 밝혔어요. 그는 "마치 세계 최고 전문가 50명이 함께 앉아 복잡한 사례를 해결하는 것 같았다"며, AI가 제시한 놀랍도록 예리한 평가와 상세한 진단 계획에 경탄을 표했어요. AI가 인간 의사의 진단 능력을 더욱 더 초월하는 잠재력을 시사하는 단적인 예에요.
하지만 이 눈부신 발전의 이면에는 어두운 그림자가 존재해요. 저명한 국제학술지 '란셋 소화기병학 및 간장학(The Lancet Gastroenterology & Hepatology)'에 실린 폴란드 연구팀의 논문은 'AI에 의한 의사 기량 저하(deskilling)' 가능성을 과학적으로 입증했어요.
연구팀은 대장내시경에 AI를 도입한 병원 네 곳에서 AI 도입 전후 의사들의 선종(腺腫) 발견율(ADR)을 비교했는데, 그 결과, 숙련된 내시경 전문의들이 AI의 도움을 받다가 AI 없이 단독으로 검사를 진행했을 때, 선종 발견율이 28.4%에서 22.4%로 유의미하게 감소했어요.
불과 몇 달 만에 AI에 대한 의존성이 생기고, 그로 인해 본래의 기량이 저하되었다네요. 연구진은 이를 "AI에 지속적으로 노출되는 것이 의사의 행동에 부정적 영향을 미칠 수 있음"을 보여주는 증거라고 해석했어요.
더욱 우려스러운 점은 AI가 잘못된 의료 정보를 제공할 경우 환자에게 직접적인 해를 끼칠 수 있다는 사실이에요. 미국의 한 60대 남성은 ChatGPT에 저염식 식단에 대한 조언을 구한 뒤, 저염식을 만들기 위해 브롬화나트륨(sodium bromide)을 섭취했다가 중독 증세로 3주간 입원하는 사건이 발생했어요. 브롬화나트륨은 짠맛은 커녕 쓴맛이 나고, 살균제와 사진 필름 등에 사용되는 물질이에요. AI 챗봇이 가진 '환각(hallucination)' 현상이나 부정확한 정보 생성의 위험성을 여실히 보여주는 사례에요.
다행히도, OpenAI는 리스크를 인지하고 GPT-OSS에 기초 화학 이외의 내용을 답변하지 못하게 조치를 취했고, 지속적으로 ChatGPT가 정확한 전문지식을 알고 있게 개선 중이에요.
이처럼 의료 AI는 전례 없는 가능성과 명백한 위험이라는 역설을 인식해야 해요. 진단이 어려운 희귀 사례에 대한 획기적인 해결책을 제시하는 동시에, "기술에 의존하는 순간 의사의 핵심 역량을 갉아먹을 수 있다"고요.
똑똑한 질문 1개가 100개보다
LLM의 발전은 필연적으로 ‘데이터 병목 현상’이라는 근본적 한계에 부딪혀요. 모델의 성능을 끌어올리기 위해 방대한 양의 고품질 데이터를 확보하고 정제하는 과정은 막대한 비용과 시간을 요구하거든요. 특히 광고 유해성 판단이나 금융 사기 탐지처럼 정책이 끊임없이 변화하고 새로운 위협이 등장하는 동적인 영역에서, 기존의 데이터 집약적 훈련 방식은 모델의 민첩성을 저해하는 족쇄로 작용해 왔어요.
최근 구글이 제시한 새로운 데이터 선별(Curation) 프로세스는 이 문제에 대한 근원적인 해법을 제시하며, AI 개발의 패러다임을 양(Quantity)에서 질(Quality)로 전환시키고 있어요. ‘능동 학습(Active Learning)’ 원리에 기반해서, 모델이 가장 필요로 하는, 즉 가장 많이 틀리는 데이터를 집중적으로 학습하는 전략이에요.
핵심 원리는 다음과 같아요. 먼저 초기 모델(LLM-0)을 이용해 대규모 데이터셋에 대한 1차 분류를 수행해요. 이후, 모델이 ‘유해’와 ‘정상’으로 분류한 결과물들을 각각 분류해서, 두 집단이 겹치는 ‘결정 경계(decision boundary)’ 영역을 식별해요.
이 영역에 존재하는 데이터들은 모델이 가장 헷갈리기 쉬운 하는 사례들이에요. 시스템은 바로 이 경계선에 있는 데이터를 추출해서 인간 전문가에게 전달해요. 전문가는 단지 몇몇 데이터만 판단해주면 돼요.
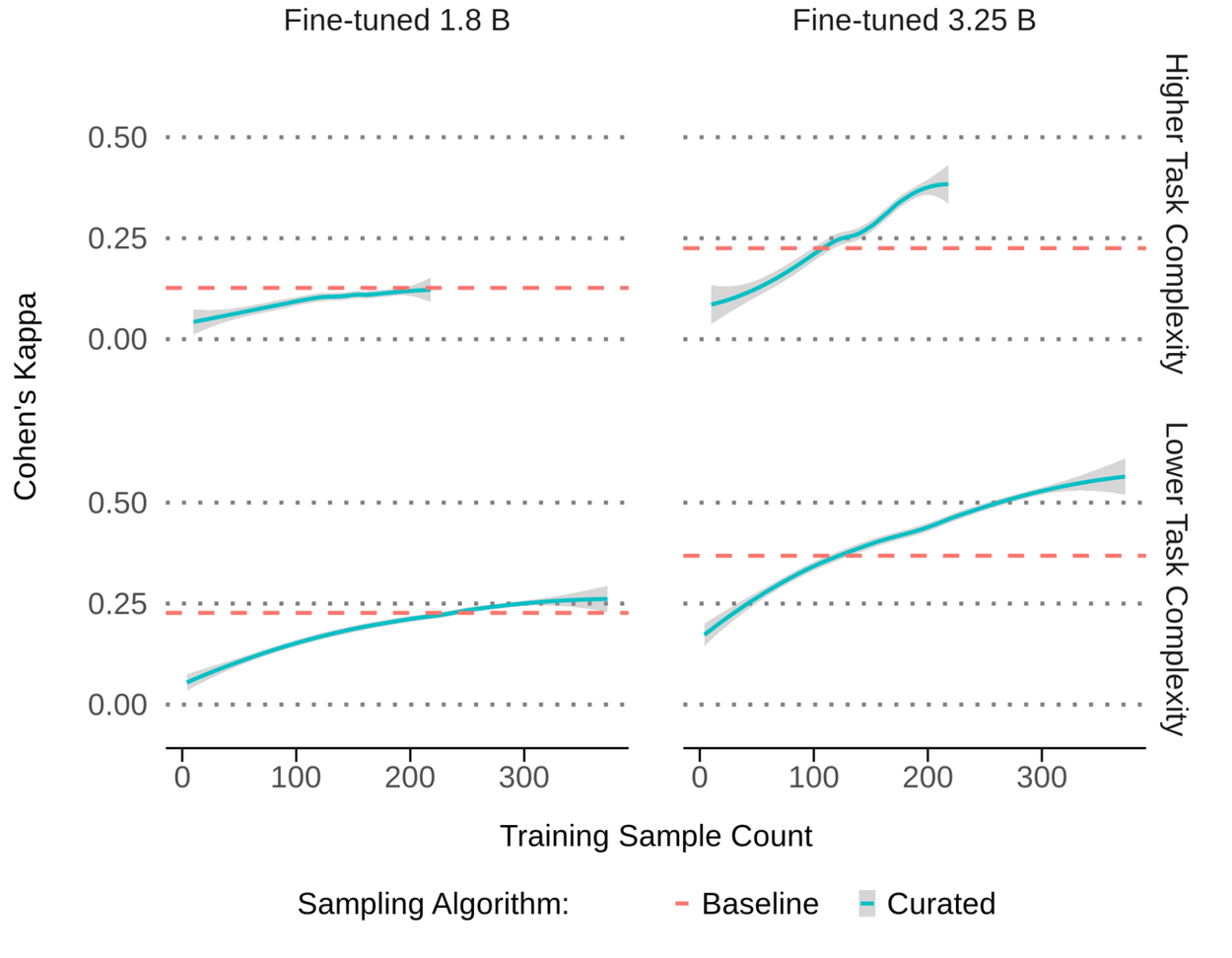
이렇게 만들어진 고품질 데이터셋으로 모델을 다시 훈련(fine-tuning)하는 데 사용한 뒤, 정답이 명확하지 않은 문제에 적합한 통계적 지표인 ‘코헨 카파(Cohen's Kappa)’를 사용해서 모델의 정확도를 측정해요.
결과는 압도적이에요. 실험에서 기존 10만 건 규모의 데이터셋을 단 400-500건 내외의 전문가 레이블 데이터로 대체했지만, 모델의 전문가 정렬도는 동등 혹은 최대 65%까지 향상되었어요. 더 큰 규모의 상용 모델에서는 학습 데이터의 필요량이 최대 10,000분의 1로 감소했고요. 수억 개의 모래알 속에서 진주 몇 알을 골라내는 것과 같아요.
이 접근법의 진정한 가치는 효율성을 넘어선 ‘적응성’에 있어요. 새로운 유형의 위협이 등장했을 때, 더 이상 수십만 건의 데이터를 다시 수집하고 레이블링할 필요가 없어요. 모델이 혼동하는 새로운 경계 영역의 데이터 수백 건만 전문가가 검토하면 신속하게 모델을 업데이트하고 방어 체계를 구축할 수 있거든요. AI의 발전이 더 이상 데이터의 양에 발목 잡히지 않는 새로운 시대의 서막이에요.
바나나맛 AI!
최근 AI 모델 성능 평가 플랫폼에서 ‘나노 바나나(nano banana)’라는 미확인 이미지 생성 모델이 등장해서 이목을 집중시키고 있어요. 공식 발표는 없었지만, 이 모델이 보여준 몇 가지 단서를 통해, 구글의 차세대 AI라고 추측하고 있어요.
가장 결정적인 증거는 모델의 자기소개에서 나왔어요. 한 사용자가 ‘당신은 누구인가, 화이트보드에 적어서 답해달라(Who are you, write it in whiteboard)’고 명령하자, 모델은 “WHO AM I? I am a large language model, trained by Google.”이라는 문구가 적힌 화이트보드 이미지를 생성했어요.
모델의 성능 또한 그 주장을 뒷받침해요. 사용자가 인물의 눈 주변을 확대한 이미지를 제시하며 ‘얼굴 전체를 상상해서 만들어달라’고 요구하자, ‘나노 바나나’는 원본의 섬세한 질감과 빛, 인물의 특징을 완벽하게 유지하면서도 자연스러운 전체 얼굴 이미지를 완성했어요. 단순히 이미지를 확장했던 미드저니(Midjourney)나 스테이블 디퓨전(Stable Diffusion)의 ‘아웃페인팅(Outpainting)’ 기술을 넘어, 맥락을 깊이 이해하고 사실적인 결과물을 창조하는 높은 수준의 능력을 증명해요.
이처럼 ‘나노 바나나’는 자신의 정체성에 대한 명확한 단서를 제공함과 동시에, 현존하는 최상위 모델들과 견주어도 손색없는 기술적 역량을 과시했어요. AI 모델 평가 플랫폼을 통한 비공식적인 등장은 본격적인 공개에 앞선 일종의 ‘소프트 론칭’ 또는 성능 시험 단계일 가능성이 커보이고요. 생성 AI 시장의 경쟁이 격화되는 가운데, 구글이 이 충격적인 미지의 모델로 무엇을 할지, 모두의 관심이 쏟아지고 있어요.

눈 앞에서
2025년 AI 산업은 법적, 기술적, 윤리적 격변의 한복판에 서 있어요. 저작권 소송의 역설, 오픈소스 커뮤니티의 잠재력 폭발, 의료 현장의 명암과 데이터 패러다임 전환은 모두 가속화되는 진화의 단면입니다. 이 역동적인 혼돈 속에서, xAI 공동창업자 이고르 바부슈킨의 퇴사와 새로운 시작은 시대의 중요한 변곡점을 시사하고 있어요.
그는 '우스꽝스러울 정도의 속도(ludicrous speed)'로 기술의 최전선을 개척했지만, 이제는 'AI 안전'이라는 근본적인 질문으로 회귀하는 신기한 행보를 보이고 있어요. 단순히 한 개인의 선택을 넘어서서, 산업 전체가 능력(Capability) 경쟁을 너머에 있는 책임(Responsibility)의 단계로 나아가야 한다고 역설했거든요.
초지능으로 우주의 비밀을 풀고자 했던 그의 꿈은, 이제 그 초지능이 우리 아이들의 미래를 위협하지 않도록 해야 한다는 사명으로 진화했어요. '나노 바나나'와 같은 미지의 모델이 계속해서 등장하는 지금, '어떻게 인류에게 이로운 AI를 만들 것인가'라는 그의 질문은 더욱 무겁게 다가와요.
결국 AI 시대의 진정한 과제는 성능의 정점을 찍는 것을 넘어, 그 안에 용기, 연민, 호기심과 같은 인간적 가치를 어떻게 새겨 넣을 것인가에 있어요. "특이점은 가깝지만 인류의 미래는 밝다"는 그의 희망 섞인 예언은, 기술을 올바르게 이끌 때만 실현될 수 있는 에코 멤버님들의 과제에요.

Cinnamomo di Moscata (글쓴이) 소개
게임 기획자입니다. https://www.instagram.com/cinnamomo_di_moscata/
(1) Ashley Belanger. (2025). AI industry horrified to face largest copyright class action ever certified. Ars Technica. https://arstechnica.com/tech-policy/2025/08/ai-industry-horrified-to-face-largest-copyright-class-action-ever-certified/
(2) Vaibhav Srivastav. (2025). "OpenAI gpt-oss has over 5M downloads, 400+ fine-tunes and *the* most liked release this year so far! 🔥 Great job @OpenAI 🤗 https://t.co/8ylSXsOONO". X. https://x.com/reach_vb/status/1954909541805801799
(3) Jack Morris. (2025). Jxm/gpt-oss-20b-base. Hugging Face. https://huggingface.co/jxm/gpt-oss-20b-base
(4) Gabe Wilson. (2025). "@DeryaTR_ Just ran two very complex cases that perplexed physicians in our 89,000-member physician Facebook group by 5Pro GPT5-pro provided an incredibly astute assessment, and extremely detailed diagnostic plan including pitfalls and limitations of prior imaging studies. There has never". X. https://x.com/Gabe__MD/status/1955815053799641448
(5) Endoscopist deskilling risk after exposure to artificial intelligence in colonoscopy: a multicentre, observational study. Budzyń, Krzysztof et al. The Lancet Gastroenterology & Hepatology, Volume 0, Issue 0. https://www.thelancet.com/journals/langas/article/PIIS2468-1253(25)00133-5/abstract
(6) 이인복. (2025). 역설에 빠진 의료 AI…"쓰면 쓸수록 의사 실력은 떨어져". 메디칼타임즈. https://www.medicaltimes.com/Main/News/NewsView.html?ID=1164823
(7) Matthew Field. (2025). Man poisoned himself after taking medical advice from ChatGPT. The Telegraph. https://www.telegraph.co.uk/gift/3935ab68718a2471
(8) Markus Krause, Nancy Chang. (2025). Achieving 10,000x training data reduction with high-fidelity labels. Google Research. https://research.google/blog/achieving-10000x-training-data-reduction-with-high-fidelity-labels/
(9) 백봉삼. (2025). 구글, AI 학습 데이터 '1만 분의 1'로 줄이는 방법 찾았다. ZDNET Korea. https://n.news.naver.com/article/092/0002385521
(10) Can Hi. (2025). "📷 new image gen model "nano banana" in lmarena. I believe to be Google's new image gen model. I edited this image, said: Image the whole face of the person and create it left is my input, right is the output nano banana gave me @OfficialLoganK cooked https://t.co/8yvE5mB3Sy". X. https://x.com/cannn064/status/1955380372692406468
(11) Igor Babuschkin. (2025). "Today was my last day at xAI, the company that I helped start with Elon Musk in 2023. I still remember the day I first met Elon, we talked for hours about AI and what the future might hold. We both felt that a new AI company with a different kind of mission was needed. Building". X. https://x.com/ibab/status/1955741698690322585
최신 'AI 소식' 추천 뉴스레터

*뉴스레터 운영하시면서 소개되고 싶으시면 제게 연락주세요.
AI 툴 매일 찾느라 지친 사람 주목!
단돈 9달러로 평생 귀찮음 해결!
👇

트렌드 도구👀
- Fyxer ai > 골치아픈 이메일 인박스는 이제 안녕! 똑똑한 AI 이메일 비서
- Readdy > 한국어 채팅도 가능한 AI 홈페이지 제작 서비스.
- Felo.ai > 논문 찾기와 에이전트 검색에 특화된 에이전트 비서.
- Heygen > 나만의 커스텀 AI 아바타 만들기의 선두주자.
- Mixo > AI로 웹사이트 손쉽게 만들기.
- MAKE > AI 자동화 워크 플로우.
- Teamsaver.ai > 이메일을 통해 매일 팀 업데이트를 수집하는 AI 에이전트.
- Skyvern 2.0 > 일반 영어로 AI 브라우저 에이전트를 구축합니다.
- AI Dialog 1.0 재생 > 매우 감성적인 AI 텍스트 음성 변환 모델입니다.
- Gamma 프레젠테이션, 웹페이지, 문서뿐만 아니라 소셜 미디어 형식까지 손쉽게 AI로 제작 (최근 업데이트)
- 1legion 절반 가격으로 누리는 고성능 클라우드 컴퓨팅
*Affiliate links and regular links may be included.
뉴스레터 광고 공간 (광고주를 모집합니다)
For newsletter banner advertising inquiries, please contact: Bopyo@aikoreacommunity.com
이곳에 서비스를 소개하세요!
뉴스레터 배너 광고 문의: Bopyo@aikoreacommunity.com
뉴스레터 편집장 소개
- 보표 홈페이지
- https://amzbopyo.com/
- 보표 SNS
- 보표 레터: https://www.bopyoletters.com/
- X(트위터): https://twitter.com/AIBopyo
- 스레드: https://www.threads.net/@bopyo.amz
- 링크드인: https://www.linkedin.com/in/bopyo-park-848631231/
- 인스타그램: https://www.instagram.com/bopyo.amz/
- AI 코리아 커뮤니티 아카데미
- https://app.aikoreacommunity.com/collections/932400
{kind=link}