

Stable Diffusion 3 등장! 초고속으로 진화하는 AI!
아직 Stable Cascade가 나온지 얼마 안되었는데도
Stable Diffusion 3는 스태빌리티 AI(Stability AI)가 개발한 최신 AI 모델이에요. 이 모델에 대해 알려진 것은 아직까지 많지 않지만, 디퓨전 트랜스포머 아키텍처라고 불리는 여러 신기술들을 사용하여 다중 주제 프롬프트, 이미지 품질, 철자 능력 등의 성능을 크게 향상시켰다고 해요.
새로운 모델의 사이즈는 그 성능만큼이나 커서, 80억(8B) 개의 패러미터가 있다고 하는데, 유저들이 추측한 바에 따르면 개인이 사용하기에는 너무 커서 RTX 4090같이 매우 비싼 GPU를 사용하는 컴퓨터가 되어야 쓸 수 있다고 해요.
다행스럽게도, 스태빌리티 AI의 CEO인 에마드 모스타크(Emad Mostaque)의 X에 따르면, Stable Diffusion 3는 양자화(quantisation)라고 불리는 기법을 적극적으로 쓸 수 있어서, 연구자들이 노력하면 지금같이 개인도 손쉽게 쓸 수 있다고 하니, 비싼 컴퓨터를 맞추려는 부담은 하지 않아도 될 것 같아요.
아쉽게도, 현재 이 모델은 공개 출시 전에 성능과 안전성을 개선하기 위한 미리보기(preview) 단계에 있다고 해요. 하지만, 하루라도 빨리 써보고 싶으신 분들이라면 여기에서 미리보기에 참가하기 위한 대기 명단에 등록할 수 있다고 해요.


사람의 말을 못알아듣는 AI, 토큰화가 문제였다고?!
AI 분야의 전문 연구원인 안드레이 카파티(Andrej Karpathy)와 얀 르쿤(Yann LeCun)은 텍스트 토큰화(Tokenisation)가 ChatGPT같은 AI가 가끔씩 선보이는 이상한 행동과 문제의 근원이 될 수 있다고 지적했어요.
토큰화는 글자를 기계어인 0과 1로 바꾸는 작업인데, 이 작업을 거치게 되면, 설령 인간이 보기에는 멀쩡한 문장이라도, 단어의 한 가운데에서 끊어버리거나, 혹은 문장을 이상하게 끊어버린 상태에서 곧바로 AI가 이해할 수 있게 중역하기 때문에 AI가 엉뚱한 대답을 내뱉는 것이 당연하다고 해요.
예시로, 'AI / 코리아 / 커뮤니티'라는 문장이 있다면, 인간은 이것은 그대로 이해하지만, AI를 위해 토큰화를 거치게 되면 'AI코 / 리아커 / 뮤니 / 티'과 같이 이상하게 끊어진 상태에서 0과 1로 번역하게 되니, 인간도 모르는데 AI라고 이해하지 못하는 게 당연할 거에요.
더욱 우려되는 점은 토큰화는 이미지나 영상 AI에서도 사용되기 때문에 오류를 퍼뜨리면 퍼뜨렸지 성능을 올리지 못한다는 점이에요. 그래서 얀 르쿤은 궁극적으로 토큰화 과정을 완전히 제거할 수 있는 방법을 찾는 것이 이상적이라고 했지만, 구체적인 방법은 제시하지 않았어요.
과연 얀르쿤은 어떤 방식을 써서 토큰화보다 뛰어난 방식을 제시할까요?
뿔난 일론 머스크가 또 무엇을?!
일론 머스크(Elon Musk)는 최근 트윗에서 테슬라의 비디오 생성 기술이 OpenAI의 Sora보다 뛰어난 이유를 물리 예측 능력 때문이라고 언급했어요. 그는 이 능력이 셀프 드라이빙 자동차 개발에 필수적이라고 강조했는데, 왜냐하면 테슬라의 자동차에 탑재되는 FSD AI는 실제 사람이나 동물, 도로 등을 구분해야 되서 그렇다고 하네요.
그는 또한 xAI의 그록(Grok) 프로젝트가 중요한 이유를 언급하며, 현재 완벽하지는 않지만 빠르게 발전하고 있으며 2주 안에 V1.5 버전이 출시될 것이라고 말했어요. 마지막으로 머스크는 비판을 무릅쓰고 진리를 추구하는 것이 중요하다고 언급했는데, 이번에 터진 제미나이(Gemini)의 이미지 생성 이슈를 생각해 볼 때, 어쩌면, 일론 머스크는 자신들보다 뛰어난 성능의 AI를 가지고 있다면 너무 부러운 나머지 일단 시샘하고 보는게 아닐까 생각해요.
구글도 이제는 오픈 소스!
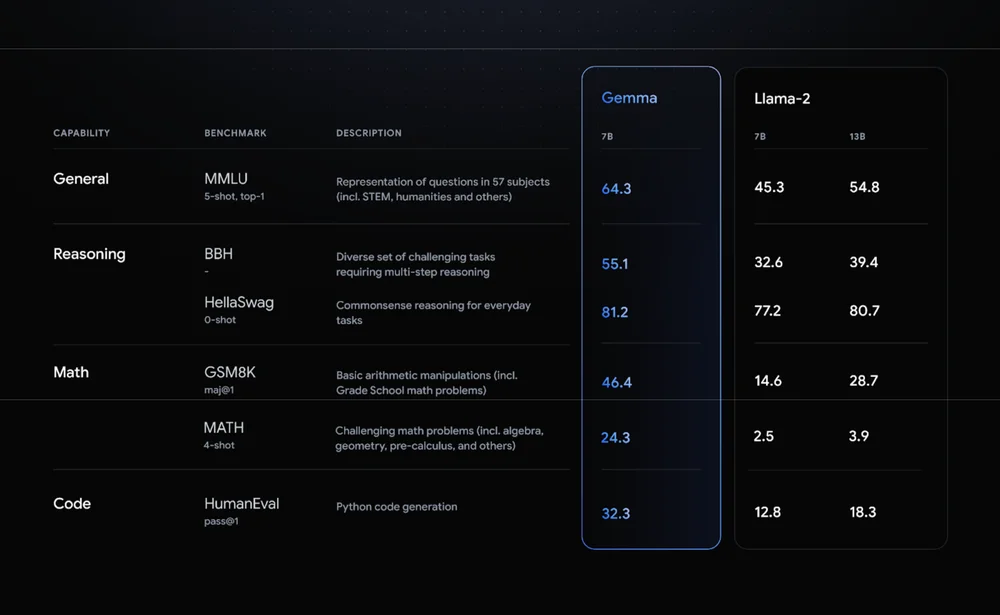
2024년 2월 22일, 구글은 인공지능(AI) 접근성을 높이는 새로운 도약을 이루는 젬마(Gemma)라는 최첨단 오픈 모델을 출시했어요. Gemma는 가볍고 효율적인 모델로, 누구나 쉽게 AI 기술을 쓸 수 있도록 하기 위해 메타(Meta)의 라마(Llama)처럼 오픈 소스로 공개했다고 해요.
젬마는 다음과 같은 특징을 가지고 있다고 해요.
두 가지 모델: 젬마는 20억(2B)과 70억(7B) 두 가지 모델이 있다고 해요. 2B 모델은 스마트폰에서도 쓸 수 있을 정도로 가벼운 모델이고, 7B 모델은 더 좋은 성능을 원할 때 쓰는 모델이에요.
책임 있는 AI: 젬마는 안전하고 윤리적인 AI 개발을 계속 강조해온 Google의 노력을 보여준다고 해요. 모델에는 편향 감소 및 안전성 검증 기능이 내장되어 있는데, 이 기능을 쓰면 자칫 나쁜 사람들이 안좋은 목적으로 쓰는 것을 막을 수 있다고 해요.
다양한 플랫폼 지원: 젬마는 랩톱, 데스크탑, IoT, 모바일 및 클라우드 등 다양한 장치에서 사용할 수 있게 만들어서 가능한 많은 사람들이 AI의 축복을 받을 수 있게 개량했다고 해요.
프롬프트 엔지니어링의 한계는 어디까지?!
이번 2월 6일에 구글 딥마인드(Google DeepMind)가 AI의 성능을 스스로 향상시키는 프롬프트 엔지니어링인 '자기 발견' 방식을 발표했어요.
기존의 AI 같이 인간이 일일히 프롬프트를 작성하여 학습시키는 방식은 시간과 노력이 많이 들고 AI도 성장하기 어려웠던 반면, 이 '자기 발견' 프롬프트 엔지니어링은 마치 인간 아이가 스스로 세상을 탐험하며 배우는 것과 비슷하게 작동한다고 해요.
더욱 놀라운 점은, 이 기술은 프롬프트 엔지니어링이기 때문에 다양한 AI 모델에 적용한 결과, 모델의 논리적 추론 능력과 문제 해결 능력이 획기적으로 발전했다고 해요.
매일 한 발짝 더
AI 기술은 빠르게 발전하고 있고, 이번 2월에도 더욱 놀라운 속도로 진화하고 있어요. Stable Diffusion 3의 등장은 이미지 AI의 새로운 가능성을 보여주었고, 안드레이 카파티와 얀 르쿤의 비판은 AI의 한계를 극복하기 위한 노력을 보여줘요. 또한, 일론 머스크의 트윗은 AI 기술 경쟁의 치열함을 보여줘요. 심지어 구글은 이번에 젬마 출시를 시작으로 오픈 소스를 중요시하기 시작했어요. 이처럼 모두가 더 좋은 성능의 AI에 집중하는 세계에서는 에코 멤버님들도 과감하게 AI를 믿고 자신이 할 수 없었던 일들에 도전하는 것이 필요하다고 생각해요.
Cinnamomo di Moscata (글쓴이) 소개
게임 기획자를 준비중입니다. AI 아티스트로도 활동하고 있습니다. Stable Diffusion을 주로 사용합니다. https://www.instagram.com/cinnamomo_di_moscata/
(1) Stability AI. (2024). "Announcing Stable Diffusion 3, our most capable text-to-image model, utilizing a diffusion transformer architecture for greatly improved performance in multi-subject prompts, image quality, and spelling abilities. Today, we are opening the waitlist for early preview. This phase… https://t.co/FRn4ofC57s". X. https://twitter.com/StabilityAI/status/1760656767237656820
(2) Andrej Karpathy. (2024). "We will see that a lot of weird behaviors and problems of LLMs actually trace back to tokenization. We'll go through a number of these issues, discuss why tokenization is at fault, and why someone out there ideally finds a way to delete this stage entirely. https://t.co/5haV7FvbBx". X. https://twitter.com/karpathy/status/1759996551378940395
(3) Yann LeCun. (2024). "Text tokenization is almost as much of an abomination for text as it is for images. Not mentioning video.". X. https://twitter.com/ylecun/status/1760315812345176343
(4) Elon Musk. (2024). "@Scobleizer Where Tesla video generation exceeds OpenAI is that it predicts extremely accurate physics. That is essential for self-driving.". X. https://twitter.com/elonmusk/status/1759305974093877282?t=hN_rUCCoe9JqmqvzKmaRRg&s=19
(5) Elon Musk. (2024). "Perhaps it is now clear why @xAI’s Grok is so important. It is far from perfect right now, but will improve rapidly. V1.5 releases in 2 weeks. Rigorous pursuit of the truth, without regard to criticism, has never been more essential.". X. https://twitter.com/elonmusk/status/1760504129485705598
(6) Jeanine Banks, Tris Warkentin. (2024). Gemma: Introducing new state-of-the-art open models. Google. https://blog.google/technology/developers/gemma-open-models/
(7) 임대준. (2024). 구글, LLM이 스스로 성능 향상하는 '자기 발견' 프롬프트 방식 공개. AI타임스. https://www.aitimes.com/news/articleView.html?idxno=157130

![[심층 분석] 1인 유니콘의 탄생: 샘 알트만의 예언은 어떻게 현실이 되었나?](/content/images/size/w1272/2026/04/---------------.png)
{kind=link}