


AI가 달리자 인간이 던지는 질문
또다른 AI 기반 합금!
고엔트로피 합금(HEA, High-Entropy Alloy)은 여러 주원소를 동시에 섞어 만드는 소재예요. 뛰어난 기계적 강도와 내산화성 덕분에 극한 환경에서도 끄떡없는 구조용 재료로 주목받고 있죠. 그런데 지금까지 HEA 설계에는 커다란 제약이 있었어요. 모든 원소를 비슷한 비율로 섞는 '등원자(equiatomic)' 방식이 거의 유일한 설계 공식처럼 통용되어 왔거든요.
문제는 이 방식이 얼마나 좁은 시야인지에 있어요. 5가지 원소로 이루어진 5원계 시스템에서 1 at.% 단위로 조성을 탐색하면, 사실상 전체 조성 공간의 1%도 채 탐색하지 못하는 셈이에요. 나머지 99% 이상의 비등원자(non-equiatomic) 영역에는 아직 인류가 발견하지 못한 고성능 합금이 잠들어 있을 수도 있어요.
이 광활한 미탐색 영역을 개척하기 위해, 물리 지식과 AI를 결합한 '지식 강화형(knowledge-enhanced) AI 프레임워크'가 개발됐어요. 순수한 데이터 기반 머신러닝(ML, Machine Learning)은 데이터가 희소한 비등원자 영역에서 과적합(overfitting)이 일어나고 물리적 해석력이 떨어지는 한계가 있어요.
이 프레임워크는 그 한계를 두 가지 모듈로 우회해요.
첫 번째 모듈은 합금의 '상(phase)'을 예측해요. 원자 크기 차이(δ), 혼합 엔탈피(ΔHmix), 원자가 전자 농도(VEC, Valence Electron Concentration) 등 7가지 물리 기반 기술자(descriptor)를 학습한 분류기(classifier)가 핵심이에요. 문헌 데이터로 훈련된 이 모델은 면심입방(FCC, Face-Centered Cubic) 및 체심입방(BCC, Body-Centered Cubic) 단상 구조 예측에서 각각 0.96과 0.94의 F1 스코어를 기록하며 신뢰성을 입증했어요.
두 번째 모듈에서는 대형언어모델(LLM, Large Language Model)이 자율 추론 에이전트(Agent)로 활약해요. LLM이 논문과 열역학 원리를 능동적으로 종합해 물리적으로 타당한 설계 규칙을 스스로 도출하는 방식이에요.
결과물로 6원계 비등원자 단상 FCC 합금인 Co₂₂Cr₂₄Fe₂₀Ni₂₅Mo₅Mn₄가 설계됐어요. 900°C에서 100시간 동안 산화 실험을 진행한 결과, 산화 속도 상수(kp)는 1.41 × 10⁻⁸ mgⁿ·cm⁻²ⁿ·h⁻¹를 기록했어요. 반응 차수(n)는 45.35로, 자가 제한적(self-limiting) 산화 체제에 진입하는 기준인 n ≥ 3을 훌쩍 초과한 수치예요.
이 뛰어난 내산화성의 비결은 이중 산화물 스케일(oxide scale)의 시너지에 있어요. 내부에는 Cr₂O₃ 장벽이, 외부에는 (Mn,Fe)Cr₂O₄ 스피넬(spinel) 완충층이 형성되는데요, 망간(Mn)의 전략적 첨가가 스피넬 형성을 촉진하고 크롬(Cr) 휘발을 억제하면서 산화물 층의 연속성을 유지해요. 내부 장벽은 금속 양이온이 밖으로 빠져나가는 것을 막고, 외부 완충층은 산소가 안으로 침투하는 것을 차단하는 이중 방어막이에요.
물리 기반 머신러닝과 LLM 추론을 결합한 이 프레임워크는 방대한 물성 데이터베이스 없이도 목적에 맞는 비등원자 합금 설계를 가능하게 해요. 광활한 조성 공간을 데이터 효율적으로 탐색하여 신소재 발굴을 크게 앞당기는 핵심 방법론으로 자리잡을 거예요.
수학의 교차점!
AI의 수학적 추론 능력이 빠르게 향상되면서, AI가 수학 연구에서 어떤 역할을 맡을 수 있는지에 대한 논쟁이 뜨거워지고 있어요. 흥미롭게도 AI 개발자들과 수학자들 사이에는 꽤 선명한 시각차가 존재해요.
AI 개발자들은 모델 성능이 '로그 통과율(log passrate)'의 형태로 향상된다고 분석해요. 평가 지표에서 약 30%의 임계점을 넘는 순간, 이후 문제 해결 능력은 기하급수적으로 치솟아요. 국제수학올림피아드(IMO, International Mathematical Olympiad) 수준의 정형화된 문제에서 AI가 거둔 성과가 이를 잘 보여주죠. 강화학습(RL, Reinforcement Learning)의 특성상 검증이 가능한 명확한 문제일수록 모델 성능이 빠르게 향상돼요.
반면 순수 수학계의 시각은 좀 더 신중해요. 토론토 대학(University of Toronto)의 다니엘 리트(Daniel Litt)를 비롯한 수학자들은 지금의 AI가 수학자들이 실제로 중요하게 여기는 연구 영역에 미친 영향은 아직 미미하다고 평가해요. 이들의 핵심 논거는 이래요.
수학 연구의 본질은 주어진 문제를 푸는 '문제 해결(Problem-Solving)'이 아니라, 새로운 개념과 구조를 정립하는 '이론 구축(Theory-Building)'에 있다는 거예요. AI는 엄밀하게 정의된 문제를 푸는 데는 능숙하지만, 새로운 추상화와 정의를 도출하는 단계까지는 아직 이르지 못했다는 주장이에요.
그런데 수학계 내부에서도 반론이 나왔어요. 제이콥 츠이머만(Jacob Tsimerman)은 수학자가 연구 시간의 80% 이상을 명확한 목표 문제를 해결하는 데 쓴다고 반박해요. 이론 구축도 결국은 특정 현상을 문제로 공식화하고 이를 해결하는 과정이며, 수학 이론의 가치는 그 이론이 해결할 수 있는 문제의 수와 질로 측정된다는 거예요.
하버드 대학(Harvard University)의 애쉬빈 스와미나탄(Ashvin Swaminathan) 역시 이론 구축을 '연속된 문제 공식화 및 해결 과정'으로 볼 수 있다며, AI가 이론 구축의 영역까지 도달할 가능성을 열어두고 있어요.
이 논쟁의 밑바닥에는 결국 하나의 질문이 있어요. 수학적 성취를 무엇으로 측정할 것인가. 증명 위주의 '정리 경제(Theorem Economy)'를 넘어, 올바른 정의와 추상화를 도출하는 작업 자체가 수학적 과제로 떠오르고 있어요.
지금 AI는 수학의 영역 중 검증 가능성이 높은 문제 해결 분야부터 점유해 나가고 있어요. 앞으로의 핵심 과제는 AI가 단순한 증명 도구를 넘어 '비조합적(non-compositional) 추론'과 '이론의 추상화'까지 영역을 확장할 수 있는지에 달려 있어요. 그 답이 어느 방향으로 나오든, 수학 연구의 방법론 자체가 근본적으로 재편되는 건 이미 시작된 이야기예요.
풍요와 인간의 조건
AI는 인간의 일자리를 빼앗는 파괴자일까요, 아니면 인류 역사상 가장 위대한 도구일까요? 최근 샘 알트만(Sam Altman)의 인터뷰는 이 질문에 확고한 '기술 낙관론'으로 답해요. 그는 AI를 농업 혁명이나 인쇄술처럼, 인류가 더 높은 곳으로 도약하기 위해 계속해서 쌓아 올리는 '비계(Scaffolding)'로 정의해요.
가장 주목할 변화는 AI가 단순한 텍스트 생성을 넘어 과학적 '추론(Reasoning)'의 영역으로 진입하고 있다는 점이에요. "예측은 지능과 매우 가깝다"는 일리야 수츠케버(Ilya Sutskever)의 통찰처럼, 세상의 방대한 데이터를 압축하고 다음을 예측하는 AI의 능력은 이제 인류의 집단 지성을 모방하는 수준에 이르렀어요. 알트만은 향후 AI가 수십 년간 풀리지 않은 수학 난제를 해결하고, 새로운 물리학 법칙을 발견하며, 암 치료를 위한 개인 맞춤형 백신을 설계하는 등 과학적 발견의 속도를 폭발적으로 앞당길 것이라 확신해요.
자연스레 '일자리 소멸'에 대한 대중의 두려움이 뒤따르는데요, 올트먼은 과거의 모든 기술 혁명이 그랬듯 일자리는 완전히 사라지기보다 형태가 변할 것이라고 단언해요. 오히려 AI라는 강력한 무기를 손에 쥔 1인 기업이나 소규모 팀이 과거에는 상상도 못 할 막대한 가치를 창출하는 시대가 열리고 있다고요.
이 지점에서 알트만이 짚어낸 '풍요의 역설'은 무척 흥미로워요. AI가 인간의 모든 노동을 대신해 완벽한 풍요와 스트레스 없는 세상을 제공한다면, 우리는 온전히 행복해질까요? 그의 대답은 '아니오'예요. 인간은 본능적으로 역경을 극복하고 성취감을 갈망하도록 진화했어요. AI가 지루하고 반복적인 과제를 모두 해결해 준다 해도, 우리는 끊임없이 새로운 우주를 탐험하고 새로운 예술과 게임을 발명하며 스스로 '의미 있는 고난'을 찾아 나설 거라는 거예요.
물론 낙관론 이면에는 현실적인 장벽도 있어요. 가상 세계에서의 AI 발전 속도에 비해, 이를 물리적으로 뒷받침할 데이터센터(Data Center)와 전력 인프라, 그리고 로보틱스(Robotics)의 발전은 여전히 인류가 풀어야 할 거대한 숙제로 남아 있거든요.
AI 인프라의 역설
일론 머스크(Elon Musk)가 이끄는 xAI는 멤피스(Memphis)와 콜로서스(Colossus) 데이터센터 클러스터에 엔비디아(NVIDIA) H100 및 H200 GPU를 무려 55만 대 규모로 구축하며 막대한 컴퓨팅 자원을 확보했어요. 하지만 IT 전문 매체 디 인포메이션(The Information)의 최근 분석에 따르면, 이 거대한 인프라의 실제 하드웨어 활용률은 고작 11% 수준에 불과하다고 해요. 물리적으로 설치된 GPU 중 실질 연산에 투입되는 건 약 6만 대에 그친다는 뜻이에요.
경쟁사와 비교하면 격차가 더욱 선명하게 드러나요. 구글(Google)과 메타(Meta)는 자체 인프라와 소프트웨어 최적화를 통해 각각 46%, 43%의 GPU 활용률을 달성했거든요. xAI의 11%는 업계 표준인 35-45% 범위에도 크게 못 미치는 수치예요.
이 격차의 핵심 원인은 분산 학습 네트워크(Distributed Training Network)와 데이터 처리 파이프라인(Pipeline)의 성숙도 결여에 있어요. 1,000-10,000대 규모의 클러스터에서는 잘 드러나지 않던 GPU 유휴 시간(Idle Time) 오류가, 수십만 대 단위의 초거대 환경으로 스케일업(Scale-up)되면서 기하급수적으로 누적된 결과예요.
이 사례는 초거대 AI 모델 학습에서 연산 효율성이 단순한 하드웨어 축적만으로는 보장되지 않는다는 사실을 명확히 보여줘요. 클러스터가 거대해질수록, 연산 자원을 분배하고 병렬 처리 과정의 지연을 통제하는 소프트웨어 아키텍처(Architecture) 역량이 진짜 경쟁력이 되는 거예요.
현재 xAI는 시스템 최적화를 통해 활용률 50% 달성을 1차 목표로 설정했어요. 나아가 에이전틱 AI(Agentic AI) 등 새로운 워크로드(Workload)에 맞춰 유휴 GPU 자원을 외부 임대 서비스로 할당하는 계획도 수립 중이에요. 장기적으로는 인텔(Intel)의 14A 공정을 활용한 자체 AI 칩 설계 프로젝트 '테라팹(TeraFab)'을 통해 범용 GPU 의존에서 벗어나 하드웨어를 내재화하는 방향을 모색하고 있어요.
학습 교과서도 AI가 스스로!
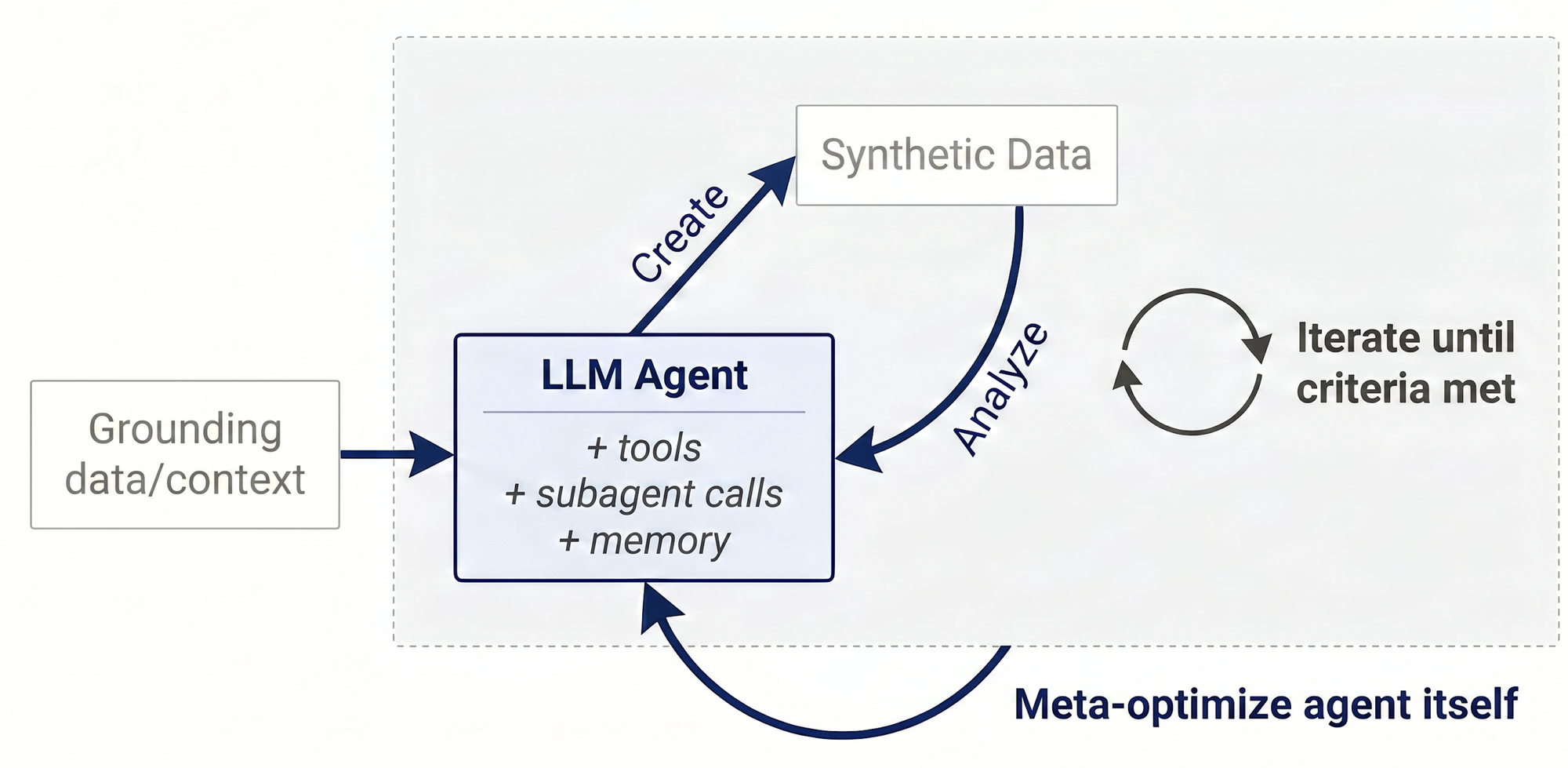
AI 모델 훈련 데이터의 중심이 인간이 직접 만든 데이터에서 AI가 스스로 생성하는 합성 데이터(Synthetic Data)로 이동하고 있어요. 기존의 셀프-인스트럭트(Self-Instruct) 기법은 데이터 생성 이후 필터링에만 의존할 뿐, 생성 과정에서 품질을 직접 제어하기 어렵다는 한계가 있었어요. 이를 해결하기 위해 AI 에이전트가 데이터 과학자 역할을 맡아 고품질 데이터를 반복 생성하고 검증하는 '오토데이터(Autodata)' 프레임워크가 등장했어요.
오토데이터는 네 가지 에이전트가 유기적으로 협력하는 구조예요. '메인 에이전트(Main Agent)'가 전체 파이프라인을 조율하고, '챌린저(Challenger)'가 초기 컨텍스트(Context)와 질의, 모범 답안, 평가 루브릭(Rubric)을 생성해요.
'약한 풀이자(Weak Solver)'와 '강한 풀이자(Strong Solver)' 두 모델이 질문을 풀고, '판사(Judge)'가 루브릭을 기준으로 두 풀이자의 답안을 평가해 점수와 성능 격차 데이터를 메인 에이전트에게 반환하는 방식이에요.
오토데이터의 핵심은 두 풀이자 간의 성능 격차를 극대화하는 방향으로 데이터를 정제하는 데 있어요. 단발성 프롬프트 기반의 CoT(Chain-of-Thought) 셀프-인스트럭트 방식에서는 두 모델의 정답률 격차가 겨우 1.9%p에 불과했어요.
반면 에이전틱 셀프-인스트럭트(Agentic Self-Instruct) 루프를 거친 데이터는 강한 모델의 정답률을 77.8%로 유지하면서 약한 모델의 정답률을 43.7%까지 떨어뜨려 성능 격차를 34.1%p로 크게 벌렸어요.
이 데이터가 모델의 고차원 추론 능력을 변별하는 데 효과적이라는 증거예요. 이 데이터로 Qwen-3.5-4B 모델에 GRPO(Group Relative Policy Optimization) 강화학습을 적용한 결과, 기존 CoT 기반 데이터로 훈련한 모델에 비해 유의미한 성능 향상을 기록했어요.
더 나아가 오토데이터는 데이터 과학자 에이전트 자체의 성능을 높이는 '메타 최적화(Meta-Optimization)' 루프도 지원해요. 에이전트가 실패한 데이터 궤적을 스스로 분석해 시스템 구조를 수정하는 방식인데요, 컴퓨터 과학 논문 질의응답(QA, Question Answering) 과제에 적용한 결과 233번의 반복 주기를 거치며 데이터 검증 통과율(Validation Pass Rate)을 12.8%에서 42.4%로 끌어올렸어요.
오토데이터는 추론 컴퓨팅(Inference Computing) 자원을 고품질 훈련 데이터 생성으로 전환하는 구체적인 방법론이에요. 에이전트 간 상호작용을 통해 데이터의 난이도와 유효성을 독립적으로 검증하는 이 구조는, 향후 AI 모델 자가 발전 파이프라인의 핵심 기반이 될 거예요.
전쟁의 여파와 기술 혁신 사이
메타(Meta)의 1분기 실적 발표 후 주가가 8% 하락하면서 시장의 우려가 커졌어요. 마크 저커버그(Mark Zuckerberg) CEO는 최근 사내 회의에서 그 배경과 향후 계획을 솔직하게 털어놓았는데요, 그의 발언을 들여다보면 빅테크(Big Tech) 기업들이 직면한 지정학적 위기와 AI라는 거대한 기술적 파도가 어떻게 맞물려 있는지 선명하게 드러나요.
저커버그는 광고 매출 성장세가 둔화된 주요 원인으로 지난 2월 말 발발한 미국과 이란 전쟁을 꼽았어요. 전쟁으로 유가가 급등하면서 소비자들이 유류비 등 필수재 지출을 늘렸고, 자연스레 임의소비재 지출이 줄어 기업들의 광고 집행 축소로 이어졌다는 거예요. 통제할 수 없는 글로벌 불확실성이 실리콘밸리(Silicon Valley) 기업의 핵심 수익 모델에 직격탄을 날리는 현실이에요.
더 주목해야 할 부분은 5월로 예정된 추가 감원의 이유예요. 저커버그는 이를 'AI 인프라 투자 비용' 때문이라고 설명했어요. 기업의 핵심 비용 구조를 '컴퓨팅(기계)'과 '인력(사람)'으로 나눌 때, 데이터센터 등 AI 인프라에 막대한 자본을 쏟아부으려면 결국 인력 규모를 줄일 수밖에 없다는 냉혹한 현실을 인정한 거예요.
AI 기술의 도입은 기업의 업무 방식 자체도 근본적으로 바꾸고 있어요. 과거 50-100명이 필요했던 프로젝트를 이제 10명만으로 수행할 수 있게 되면서, 거대한 조직 규모가 오히려 비효율로 작용할 수 있다는 거예요.
흥미로운 건 저커버그가 잉여 인력을 단순히 해고하는 데 그치지 않고, AI로 높아진 효율성을 바탕으로 최대 50개의 새로운 앱을 개발하겠다는 청사진을 제시했다는 점이에요. 인력 부족으로 우선순위에서 밀려 있던 프로젝트들을 소규모 정예 팀으로 빠르게 실행에 옮기겠다는 전략이에요.
메타의 현주소는 오늘날 기술 기업들이 처한 딜레마(Dilemma)를 대변해요. 외부로는 전쟁과 인플레이션(Inflation)이라는 거시경제적 충격을 극복해야 하고, 내부로는 천문학적인 비용이 드는 AI 패권 경쟁에서 살아남기 위해 뼈를 깎는 구조조정을 단행해야 하죠. 기술의 진보가 기업의 구조와 노동의 가치를 근본적으로 재편하는 시대, 이미 도래했어요.
해고의 면죄부?
AI가 일자리를 대체할 것이라는 우려가 점차 현실이 되고 있어요. 기업들은 비용 절감과 효율성을 이유로 앞다투어 AI를 도입 중이고, 이 과정에서 근로자의 설 자리는 점점 좁아지고 있어요. 그런데 최근 중국 법원에서 나온 판결 하나가 기술 발전과 노동권 보호의 충돌 속에서 중요한 이정표를 제시했어요.
중국 항저우시 중급인민법원(杭州市中級人民法院)은 지난 4월, AI 도입을 이유로 직원을 부당 해고한 IT 기업에 위법 판결을 내렸어요. 대형언어모델(LLM)의 품질 보증(QA, Quality Assurance) 업무를 하던 '저우'는 AI가 자신의 업무를 대체하자 일방적인 직급 강등과 40% 급여 삭감을 요구받았어요.
이를 거부하자 회사는 인력 감축을 이유로 해고를 통보했고요. 이에 법원은 "기술 발전 자체는 기업의 경영난이나 사업 축소 등 부정적 상황에 해당하지 않으며, 근로계약을 해지할 합법적 사유가 될 수 없다"고 못 박았어요.
이 판결의 배경에는 기술 패권과 사회 안정이라는 두 마리 토끼를 동시에 잡으려는 중국 당국의 깊은 고심이 담겨 있어요. 국가 주도로 AI 기술 경쟁에 총력을 기울이면서도, 경기 둔화와 높은 청년 실업률이라는 현실 속에서 노동 시장의 붕괴만큼은 막겠다는 의지가 반영된 거예요. 지난해 12월 지도 제작 업체의 유사 판례에 이어, 이번 판결 역시 기업의 AI 도입이 무분별한 인력 감축과 임금 삭감의 구실이 될 수 없음을 명확히 했어요.
이 사안은 비단 중국만의 문제가 아니에요. 기술 혁신은 기업 생존에 필수적이지만, 그것이 인간 노동의 일방적인 배제로 이어져서는 곤란해요. 기업은 AI를 단순한 '인건비 절감 도구'로 볼 것이 아니라, 기존 인력의 직무 전환과 재교육을 통해 인간과 AI가 협업하는 새로운 환경을 조성해야 해요.
유턴!
최근 미국 트럼프(Trump) 행정부의 AI 정책에 심상치 않은 기류 변화가 감지되고 있어요. 주요 외신에 따르면, 도널드 트럼프(Donald Trump) 대통령이 새로운 AI 모델에 대한 정부 차원의 감독 및 사전 검토 절차 도입을 검토 중인 것으로 알려졌어요. AI 산업에 대해 철저한 '자유방임주의'를 외치며 빗장을 풀던 기존 행보를 180도 뒤집는 이례적인 결정이에요.
이 급격한 태도 변화의 결정적 배경에는 앤트로픽(Anthropic)이 새롭게 선보인 AI 모델 '미토스(Mythos)'가 자리해요. 사이버 보안(Cyber Security) 전문가들은 미토스의 압도적인 코딩 능력이 복잡한 사이버 공격을 기하급수적으로 고도화할 수 있다고 경고해요. 스스로 시스템의 취약점을 찾아내고 이를 악용하는 해킹 기법을 고안할 수준에 이르렀다는 거예요. 혁신의 상징이던 초거대 AI가 국가 안보를 위협하는 무기로 돌변할 수 있다는 현실적 공포가 결국 미국 정부를 움직였어요.
불과 얼마 전까지만 해도 트럼프 대통령의 기조는 명확했어요. 2025년 취임 첫날, AI 시스템의 안전성 평가 결과 제출을 의무화했던 바이든(Biden) 전 대통령의 행정명령을 전격 폐기했고, 중국과의 AI 패권 경쟁에서 우위를 점하기 위해 각종 환경 규제를 완화하고 동맹국으로의 AI 수출을 확대하는 청사진을 내놓기도 했어요. 어떠한 제약도 두지 않겠다는 강력한 의지였죠.
하지만 통제 범위를 벗어난 AI가 초래할 국가적 위협은 '규제 철폐'라는 굳건한 정치적 신념마저 꺾어버렸어요. 백악관은 현재 정부 관료와 빅테크 기업 임원들로 구성된 AI 실무 그룹을 창설하고, 공식적인 검토 절차를 마련하는 행정명령을 논의 중이에요. 무한 경쟁만을 외치기에는 AI가 품은 파괴력이 너무나 거대해졌고, 아무리 경제와 산업을 우선시하는 트럼프 행정부라 할지라도 국가 안보라는 '레드라인(Red Line)' 앞에서는 국가 개입의 필요성을 인정할 수밖에 없었던 거예요.
AI 기업들은 왜 우리에게 '공포'를 팔까
최근 실리콘밸리(Silicon Valley)의 AI 업계에서 기묘한 마케팅(Marketing)이 유행하고 있어요. 자신이 개발한 최신 AI가 "너무 강력하고 위험해서" 세상에 내놓을 수 없다고 선언하는 거예요. 앤트로픽(Anthropic)은 최신 모델 '클로드 미토스(Claude Mythos)'가 인간 전문가를 초월하는 사이버 해킹 능력을 갖췄으며, 악용될 경우 국가 안보와 경제에 심각한 위협이 될 것이라고 경고했어요.
맥도날드(McDonald's)가 "이번에 개발한 햄버거는 너무 맛있어서 파는 게 비윤리적"이라고 말하지 않듯, 이윤을 추구하는 기업이 자사 제품을 이렇게 묘사하는 건 분명 이례적이에요. 그렇다면 AI 기업들은 대체 왜 스스로 공포를 주입하려 하는 걸까요?
전문가들은 이것이 고도로 계산된 '공포 마케팅(Fear Marketing)'이라고 지적해요. 대중의 관심이 AI가 인류를 멸망시킬지도 모른다는 종말론적 시나리오에 쏠리면, 현재 AI가 야기하는 현실적이고 시급한 문제들은 상대적으로 사소해 보이게 돼요. 막대한 데이터센터 가동으로 인한 환경 파괴, 딥페이크(Deepfake)를 이용한 사기와 범죄, AI가 촉발하는 정신 건강 악화 같은 당면한 부작용들로부터 대중과 규제 당국의 시선을 가상의 먼 미래로 돌리는 전략이에요.
더 나아가 이러한 공포 서사는 기술 권력의 독점을 정당화하는 도구로도 쓰여요. 에든버러 대학(University of Edinburgh)의 섀넌 발러(Shannon Vallor) 교수의 지적처럼, 기술을 통제 불가능한 초자연적 존재처럼 포장하면 대중은 무력감을 느끼게 돼요. 이는 결국 "이 엄청나고 위험한 기술을 다루고 통제할 수 있는 건 오직 이를 만든 소수의 AI 기업뿐"이라는 착각을 불러일으키죠. 외부의 민주적 통제나 정부의 개입을 배제하고, 자신들만이 세상을 구원할 수 있다는 오만한 발상이에요.
실제로 이들의 주장은 앞뒤가 맞지 않는 경우가 많아요. 과거 OpenAI는 GPT-2 발표 당시 악용 우려를 핑계로 공개를 미루다 결국 몇 달 뒤 출시했어요. 일론 머스크(Elon Musk)는 AI 개발 일시 중단을 촉구하는 서한에 서명하고도, 불과 6개월도 채 되지 않아 자신의 AI 기업을 설립하는 모순을 보였고요. 앤트로픽 또한 미토스의 경이로운 능력을 자랑하면서도, 보안 업계의 필수 검증 지표인 '오탐지율(False Positive Rate)'은 투명하게 공개하지 않았어요.
이들 기업은 AI가 인류를 파멸시킬 수 있다고 경고하는 동시에, 기후 변화를 해결하고 전례 없는 풍요를 가져다줄 것이라는 모순된 이미지도 함께 팔아요. 천사와 악마의 두 얼굴을 앞세운 물론 AI는 인류에게 도움이 되는 기술이지만, 기이한 이 신화적 서사는 결국 상장을 앞둔 기업의 주가를 띄우고 시장을 지배하기 위한 수단에 불과해요.
기술은 달리고, 질문은 남는다
AI가 물리 법칙을 학습해 인류가 발견하지 못한 합금을 설계하고, 수학자들이 수십 년간 씨름하던 이론의 영역에 발을 들이며, 55만 개의 GPU를 쌓아 올려도 소프트웨어가 따라오지 못하면 무용지물이 된다는 것. 이 모든 이야기의 공통점은 단순히 'AI가 더 똑똑해졌다'는 데 있지 않아요. 기술이 강력해질수록, 그것을 둘러싼 인간의 선택이 훨씬 더 복잡해진다는 사실이에요.
중국 법원이 "기술 발전은 해고의 사유가 될 수 없다"고 선언하고, 트럼프 행정부가 규제 철폐의 신념을 스스로 꺾으며, AI 기업들이 공포와 유토피아를 동시에 파는 현실. 이 모든 장면은 결국 같은 질문으로 수렴해요. 이 기술을 누가, 어떤 방향으로 이끌 것인가.
속도보다 방향이, 목표 달성보다 의문이 더 중요해진 시대예요. AI가 달리는 속도는 우리가 통제할 수 없을지 몰라도, 그 옆에서 어떤 질문을 던지는가는 여전히 인간의 몫이에요. 그 질문을 멈추지 않는 것, 그것이 지금 에코 멤버님들에게 가장 필요한 경쟁력이에요.

Cinnamomo di Moscata (글쓴이) 소개
게임 기획자입니다. https://www.instagram.com/cinnamomo_di_moscata/
(1) Huang, H., Yu, Y., Deng, W. et al. Breaking equiatomic constraints: knowledge-enhanced AI framework for function-oriented single-phase high-entropy alloy design. npj Comput Mater (2026). https://doi.org/10.1038/s41524-026-02071-4
(2) Jason Tsimerman. (2026). "@littmath @willdepue Hey @littmath , I've seen you post this sentiment a lot, and want to push back a bit (in my formal twitter-posting debut!). So my math career has almost entirely been "solve this problem". Now, of course there is an enormous amount of other activities such as formulating toy". X. https://x.com/Jacob_Tsimerman/status/2050695123424399776
(3) Mert Ünsal. (2026). "@littmath @Jacob_Tsimerman @willdepue Even though I agree, one hard question for me is: Do we have another alternative to theorem proving as a measure of success after the "Fall of the Theorem Economy"? https://t.co/XVCZUHhjo7". X. https://x.com/mertunsal2020/status/2051016363184128067
(4) NothingButTech. (2026). Sam Altman's Vision For the Future!. YouTube. https://www.youtube.com/watch?v=Mklj3Y2-fNg
(5) Hassan Mujtaba. (2026). xAI Is Reportedly Using Just 11% of Its 550,000 NVIDIA GPUs, While Meta and Google Squeeze Out 43-46% From Their Fleets. wccftech. https://wccftech.com/xai-using-just-11-percent-gpus-while-meta-google-squeeze-out-much-more/
(6) Kulikov, Ilia and Whitehouse, Chenxi and Wu, Tianhao and Saha, Swarnadeep and Helenowski, Eryk and Yuan, Weizhe and Golovneva, Olga and Lanchantin, Jack and Bachrach, Yoram and Foerster, Jakob and Li, Xian and Fang, Han and Sukhbaatar, Sainbayar and Weston, Jason. (2026). Autodata: an automatic data scientist to create high quality data. Engineering at Meta. https://facebookresearch.github.io/RAM/blogs/autodata/
(7) Meghan Bobrowskyy. (2026). Mark Zuckerberg Blames Slower Sales on War, Layoffs on AI Costs in Meeting. Wall Street Journal. https://www.wsj.com/tech/ai/mark-zuckerberg-blames-slower-sales-on-war-layoffs-on-ai-costs-in-meeting-2e9f8cac
(8) Victor Swezeyy. (2026). Chinese Court Rules Firms Can’t Lay Off Workers on AI Grounds. Bloomberg. https://www.bloomberg.com/news/articles/2026-05-02/chinese-court-rules-firms-can-t-lay-off-workers-on-ai-grounds
(9) Reuters. (2026). White House considers government reviews for AI models, NYT reports. Reuters. https://www.reuters.com/world/white-house-considers-vetting-ai-models-before-they-are-released-nyt-reports-2026-05-04/
(10) Thomas Germain. (2026). Why AI companies want you to be afraid of them. BBC. https://www.bbc.com/future/article/20260428-ai-companies-want-you-to-be-afraid-of-them
{kind=link}